1 基本概念
1.1 定义
隐 Markov 模型 (Hidden Markov Model, HMM)
这是一个关于时间序列的概率模型, 描述由一个隐藏的 Markov 链随机生成不可观测的状态随机序列, 再由各个状态生成一个观测从而产生观测随机序列的过程. 隐藏 Markov 链随机生成了状态序列; 每个状态产生的一个观测生成的随机序列为观测序列.
设
- 是所有可能状态的集合, 是所有可能的观测的集合
- 在时间长度 下有状态序列 和观测序列
- 状态转移矩阵 , 其中
- 观测概率矩阵 , 其中 , , .
- 初始状态概率向量 , 其中 是 时处于状态 的概率.
因此隐 Markov 模型由 决定, 其中 决定状态序列, 决定观测序列.
隐 Markov 模型的两个基本假设:
- 齐次 Markov 性假设:
- 观测独立性假设:
| 盒子 |
1 |
2 |
3 |
4 |
| 红球 |
5 |
3 |
6 |
8 |
| 白球 |
5 |
7 |
4 |
2 |
按照下面的方法抽球, 产生一个球的颜色的观测序列:
- 等概率选择一个盒子, 随机抽一个球
- 如果当前盒子是 1, 转移到盒子 2; 如果当前盒子是 2 或 3, 分别以概率 0.4 和 0.6 转移到左边/右边的盒子; 如果当前盒子是 4, 以 0.5 的概率转移到 4/3. 然后从盒子里抽一个球
- 重复 5 次, 得到观测序列 ( 代表红, 代表白).
这里状态序列 (盒子编号) 是隐藏的, 只有颜色序列可观测. 这里状态集合 ; 观测集合为 . 序列长度 . 初始概率分布为 , 状态转移概率分布为 观测概率分布为
1.2 观测序列的生成过程
输入 隐 Markov 模型 , 观测序列长度
输出 观测序列
- 按 分布生成 , .
- 按 的观测概率分布 生成 .
- 按 的状态转移概率分布 生成 .
- 令 ; 若 , 转到 2; 否则终止.
1.3 个基本问题
- 概率计算问题: 计算
- 学习问题: 估计参数 , 使 最大
- 预测问题(解码问题): 估计状态序列 , 使 最大
2 概率计算算法
2.1 直接计算
直接计算各个概率: 对 , , 从而 最后对 求和: 这个公式是 阶的, 计算量过大.
2.2 前向算法
给定模型 , 定义前向概率 (也即给定模型下, 时刻的观测序列和状态的概率)
输入
输出
- 初值 .
- 递推:
- 终止: .
关于第二步, 根据定义 , 然后再乘上 就是 . 第三步由定义容易得到.
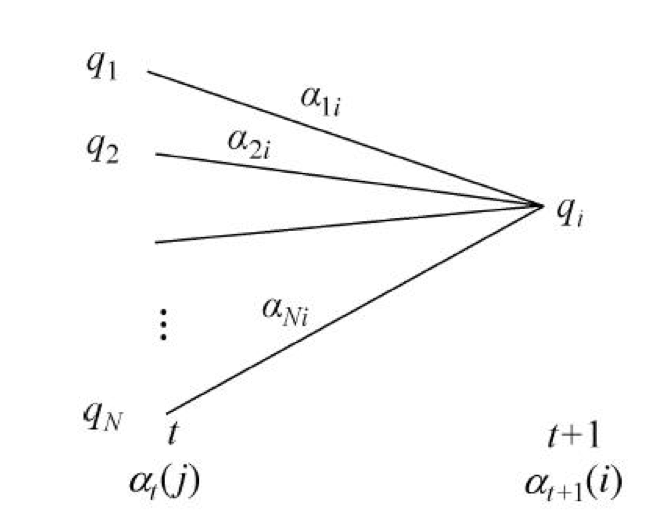
在每个时刻 , 都计算 的 个值, 可以直接利用之前的 , 避免重复计算, 这样计算量从 下降到了 .
考虑盒子和球模型. 设 , , , , 现计算 . 首先计算初值 然后递推计算 终止
2.3 后向算法
定义
输入
输出
- 对 :
-
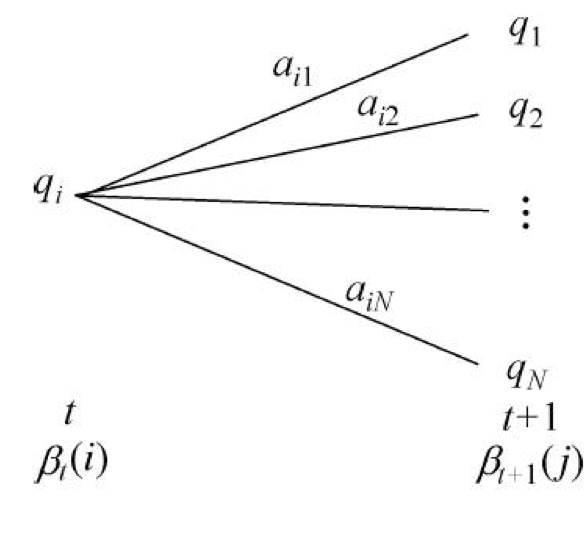
根据前向和后向概率, 可以统一
2.4 一些概率与期望的计算
-
记 . 事实上
-
记 , 则
-
基于 得到的期望值:
- 下 出现的期望: .
- 下 转移的期望: .
- 下 转移到 的期望: .
3 学习算法
3.1 监督学习算法
假设知道 个长度相同的序列: . 可以用极大似然估计来估计模型的参数.
- 转移概率 :
假设 下状态为 , 下状态为 的频数为 , 则
- 观测概率 :
设状态为 且观测为 的频数为 , 则
- : 初始状态下 的频率.
3.2 Baum-Welch 算法
人工标注数据的代价很高, 因此采用无监督学习的算法.
现在只给定 . 将观测序列看作 , 状态序列看作不可观测的 , 则隐 Markov 模型为 可以用 EM算法 实现.
- E 步: 计算 : 带入 有
- M 步: 极大化 , 求参数 . 注意到 分别出现在上面的三项中, 因此可以分别极大化. 对第一项, 结合 , 写出 Lagrange 函数 对 求偏导让结果为 , 得
类似地, 第二项可以写为 结合约束条件 , 类似得
最后对第三项 结合 , 注意要添加限定条件 , 则
结合 gamma 和 xi, 有
输入
输出
- 初始化: , 选取 , 得到模型 .
- 递推: 见 (3.1).
- 终止: .
预测算法