EM 算法用于含有隐变量的概率模型参数的极大似然估计. 它大体上分为
- E 步 (Expectation),
- M 步 (Maximization).
1 EM 算法的引入
1.1 EM 算法
设有硬币 . 正面朝上的概率分别为 . 进行如下实验: 先抛 , 正面选 , 反面选 , 根据选择的结果抛硬币, 正面记为 , 反面为 ; 独立的重复 次, 观测结果为 (我们无法看到抛硬币的过程, 只能看到结果) 现在要确定 .
为此, 将模型写作 即是隐变量, 是参数.
将观测数据表示为 , 未观测数据表示为 , 则观测数据的似然函数为 则极大似然估计为 只能通过迭代的方法求解. 我们下面直接给出 EM 算法在这里的的表达式:
选取初值 , 设第 次迭代得到 . 则在第 次,
- E 步, 计算 下 来自 的概率
- M 步, 计算新的估计值
在上面的例子中, 表示观测变量, 表示隐变量. 连在一起称为完全数据, 自己称为不完全数据. 这里 的似然函数是 , 对数似然是 . EM 算法即要求 的极大似然估计.
输入
输出 模型参数
- 选取初值 .
- E 步: 在第 次迭代, 计算
- M 步:
- 重复 2, 3, 直到收敛.
上面的 是算法核心, 称为** 函数**.
算法各步骤的说明
- 参数的初值可以任意选择, 但是 EM 算法对初值敏感.
- 尽管 的两个参数分别表示要极大化的参数和当前的估计值, 但实际上是在求 函数的极大值.
- 后面将证明每次迭代会使似然函数增大或达到局部极值.
- 体制迭代条件一般为对于较小的 ,
1.2 EM 算法的导出
我们希望极大化观测数据 关于 的对数似然函数 假设经过某种迭代后 的估计值是 , 希望新的估计值使得 增加, 也即 . 根据 Jensen不等式, , 则
令 且容易知道 因此任意让 增大的 也可以让 增大. 为了让增大尽可能大, 则
这与 (1.1),(1,2) 等价.
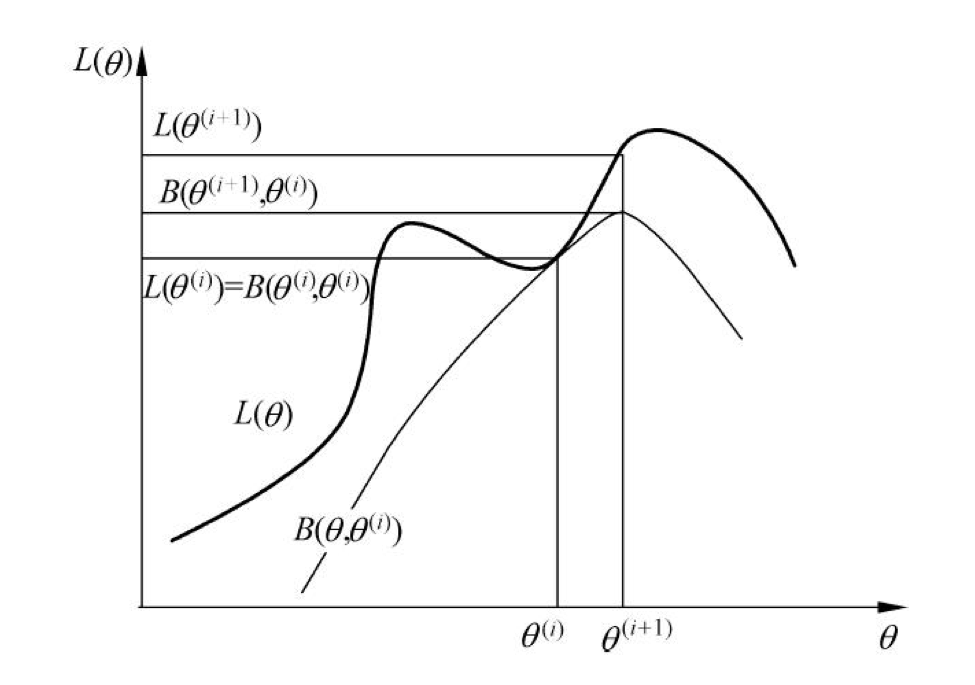
从这张图看出, 在处相等, 随着的取值, 也相应的增大, 此时的图像进行偏移, 进而迭代地找到的极大值点. 从这里也可以看出, EM 算法无法找到全剧最值点.
1.3 EM 算法在无监督学习中的应用
无监督学习的训练集为 , 每个数据点没有对应的输出. 我们可以认为需要学习联合概率分布 , 为观测数据, 为未观测数据.
2 EM 算法的收敛性
设 为观测数据的似然函数, EM 算法得到参数序列 , 则 关于 单调递增.
- 若 有上界, 则 收敛到某一个 .
- 在 与 满足一定条件下, EM 算法得到的 的收敛值 是 的稳定点.
3 EM 算法在 Gauss 混合模型学习的应用
3.1 Gauss 混合模型
有以下形式的概率分布模型 称为** Gauss 混合模型**(Gaussian mixture model, #GMM )
这里 是系数, ; , (也即 .)
注意, 这里的求和的意思是, 观测值依概率 属于第 个子模型, 而非把每个模型的密度相加.
3.2 Gauss 混合模型参数估计的 EM 算法
假设观测数据 由 (3.1) 生成, .
- ^ 明确隐变量, 写出完全数据的对数似然函数
分别是依照概率 来选择第 个 Gauss 分布模型 , 并依此生成 . 因此, 已知, 但是 来自哪个子模型 () 未知, 用隐变量 表示, 即 是 随机变量. 这样, 完全数据(回顾定义)是 . 于是写出似然函数
其中 因此对数似然函数为
- ^ E 步: 确定 函数
记 , 则
是当前模型参数下第 个观测数据来自第 个分模型的概率, 称为 对 的响应度. 将计算结果代入, 得
- ^ M 步: 迭代
对于 (3.2), 分别对 求偏导, 令其为 即可; 对于 , 在 下求偏导令为 . 最后的结果如下所示:
输入 , GMM
输出 GMM 的参数
- 选取参数初始值.
- E: 计算分模型 对观测数据 的响应度
- M: 更新模型参数
- 重复 2, 3, 直到收敛.
4 EM 算法的推广
假设隐变量 的概率分布为 , 定义 与参数 的函数 : 称为 函数. 这里的 是熵.
在定义中, 通常假设 是 的连续函数, 因此 是 的连续函数. 还有以下重要性质:
对于固定的 , 可以极大化 , 此时 由下式给出 且 关于 连续.
固定 , 引入 Lagrange 乘子 , 得到 Lagrange 函数 令
再由约束条件 得 (4.2).
若 , 则
根据 F函数的定义, 有
由引理4.1, 这个不等号要取等(因为此时 是极大值点).
, , 定义如前. 如果 在 有局部/全局极大值, 则 在 也有局部/全局极大值.
由引理4.1, 引理4.2, , . 特别地, 下面证明 也是 的极大值点, 也即不存在接近 的 , 使得 . 否则如果它存在, 那么 , 这里 . 但是因为 随 连续变化, 应该接近 , 这与 是 的局部极大值点矛盾.
全局最大值类似可证.
定理 4.2 EM 算法的一次迭代可由
函数的极大-极大算法实现.
设 为第 次迭代对应的估计, 在第 次迭代, 两步分别为
- 对固定的 , 求 使 极大化;
- 对固定的 , 求 使 极大化.
- 由引理4.1, 对固定的 , 可以极大化 . 此时
由 的定义式 (1.1),
- 固定 , 求 使 极大化, 得到
4.2 GEM 算法
输入 观测数据, 函数
输出 模型参数
- 初始化 .
- 第 次迭代,
- 求 使 极大化 .
- 求 使 极大化.
- 重复 2, 3 直到收敛.
输入 观测数据, 函数
输出 模型参数
- 初始化 .
- 第 次迭代,
- 计算
- 求 使 .
- 重复 2, 3 直到收敛.
输入 观测数据, 函数
输出 模型参数
- 初始化 .
- 第 次迭代,
- 计算
- 进行 次条件极大化.
首先, 在 不变的情况下求使 极大的 .
然后在 的条件下求使 达到极大的 .
如此继续, 经过 次条件极大化, 得到 , 使得 .
- 重复 2, 3 直到收敛.