7.1 XGBoost LightGBM
我们在 上篇笔记 中看到了 boosting 的基本思想, 以及和树模型结合后的 GBDT 模型. XGBoost 和 LightGBM 是对此的工程优化.
1 XGBoost
XGBoost 是大规模并行 boosting tree 的工具.
1.1 数学原理
1.1.1 目标函数
回到 GBDT 的基本假设: 由
在损失函数中我们加入正则项
(这里我们使用了 Boosting 加法模型的基本假设:
在第
根据这个目标函数得到每一步的
1.1.2 基于决策树的目标函数
现在将基模型引入 决策树. 记为
代入 (1.1):
1.1.3 树的划分
- 贪心算法: 在第
步, 训练一棵决策树; 首先它是一棵深度为 的树, 然后枚举可用特征. 对每个特征, 将样本对应的值升序排列, 线性扫描来决定最佳分裂点, 记录分裂收益, 选取收益最大的特征和分裂点, 以此类推. 这样, 分裂前的目标函数为 分裂后为 则分裂后的收益为
只需从左到右扫描一次, 就可以计算每个分割方案的收益.
2. 近似算法: 缓解贪心算法的内存读写压力. 对每个特征, 首先根据特征分布的分位数提出候选划分点, 然后将连续特征映射到这些候选点划分的桶中, 最后找到所有区间的最佳分裂点. 候选切分点有两种策略:
- Global (per tree): 每次学树前提出候选切分点, 每次分裂都采用这种分割; 需要更多的候选点.
- Local (per split): 每次分裂前重新提出候选切分点, 需要更多的计算步骤.
- 对每个特征
: 依据分位数得到候选集合 . 依据 Global 或 Local 策略. - 对每个特征的候选集合, 将样本映射到该特征对应候选点集构成的分桶区间中, 即
. 对每个桶统计 值, 然后寻找最佳分裂点. 也即
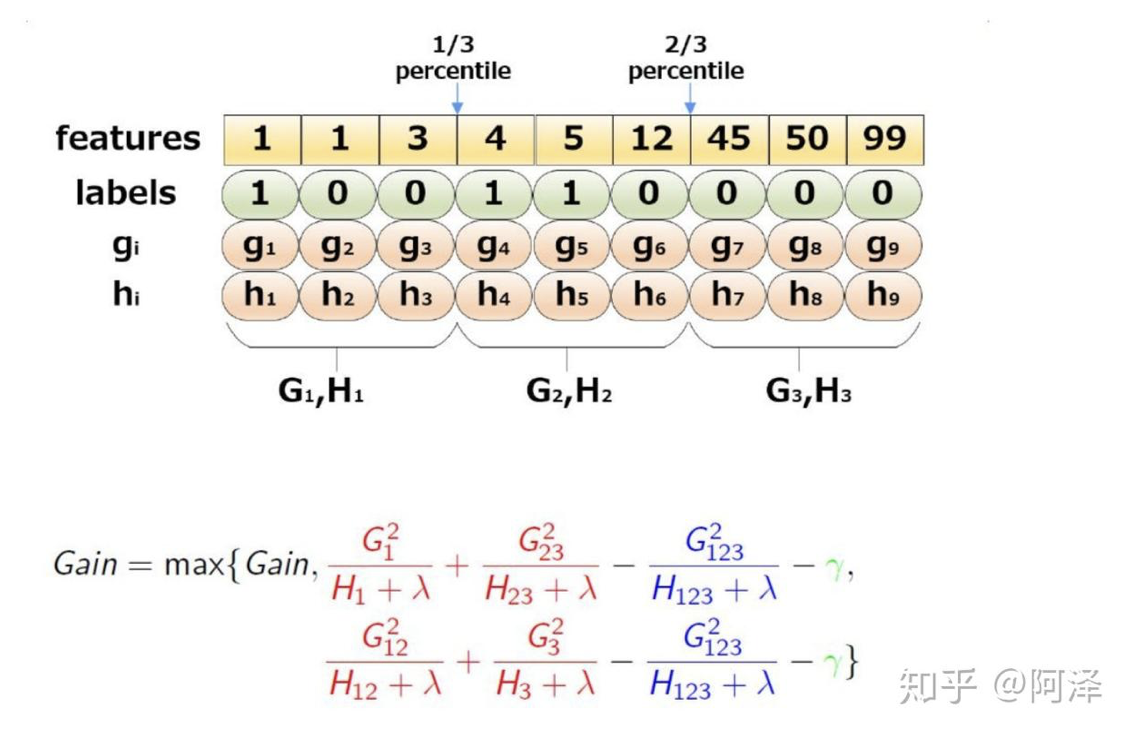
如图, 取三分位数, 则
1.1.4 加权分位数
1.2 优缺点
- 优点
- 精度更高:GBDT 只用到一阶泰勒展开,而 XGBoost 对损失函数进行了二阶泰勒展开。XGBoost 引入二阶导一方面是为了增加精度,另一方面也是为了能够自定义损失函数,二阶泰勒展开可以近似大量损失函数;
- 灵活性更强:GBDT 以 CART 作为基分类器,XGBoost 不仅支持 CART 还支持线性分类器,(使用线性分类器的 XGBoost 相当于带 L 1 和 L 2 正则化项的逻辑斯蒂回归(分类问题)或者线性回归(回归问题))。此外,XGBoost 工具支持自定义损失函数,只需函数支持一阶和二阶求导;
- 正则化:XGBoost 在目标函数中加入了正则项,用于控制模型的复杂度。正则项里包含了树的叶子节点个数、叶子节点权重的 L 2 范式。正则项降低了模型的方差,使学习出来的模型更加简单,有助于防止过拟合;
- Shrinkage(缩减):相当于学习速率。XGBoost 在进行完一次迭代后,会将叶子节点的权重乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间;
- 列抽样:XGBoost 借鉴了随机森林的做法,支持列抽样,不仅能降低过拟合,还能减少计算;
- 缺失值处理:XGBoost 采用的稀疏感知算法极大的加快了节点分裂的速度;
- 可以并行化操作:块结构可以很好的支持并行计算。
- 缺点
- 虽然利用预排序和近似算法可以降低寻找最佳分裂点的计算量,但在节点分裂过程中仍需要遍历数据集;
- 预排序过程的空间复杂度过高,不仅需要存储特征值,还需要存储特征对应样本的梯度统计值的索引,相当于消耗了两倍的内存。
2 LightGBM
主要用于解决 GBDT 在海量数据时遇到的问题, 内存占用显著更少.
2.1 数学原理
2.1.1 单边梯度抽样算法 GOSS
[1]
GBDT 中, 梯度反映了样本的权重, 梯度越小则模型拟合的约好(已经接近最好, 减小变得平缓). 所以, 只需要关注梯度高的样本, 来减小计算量.
为此, GOSS 对梯度小的样本进行随机抽样, 并引入常数进行总体样本数据分布的平衡.
具体而言, 首先对梯度的绝对值排序, 取前
2.1.2 直方图算法
也即 特征离散化, 将连续的特征变为
- 直方图加速:
依据现有的直方图直接做差.

2.1.3 互斥特征捆绑算法 EFB
这是为了解决高维特征的稀疏性. 用互斥率表示两个特征的互斥程度(是否同时取非零值). 我们关心如何找到可以绑定的特征, 以及绑定后特征值如何确定. 这里使用 贪心法 来解决 NP-Hard 的加权无向图的图着色算法:
- 根据特征的互斥关系得到一个加权无向图
- 根据节点的度降序排序: 度越大, 与其他节点的冲突越大
- 遍历每个特征, 从"新建特征包, 分配给现有特征包" 中选择总体冲突最小的方案
时间复杂度是
接下来给出特征合并算法, 它为了确保原始的特征能从合并的特征中分离出来, 为此平移每个特征的取值范围使它们互不相交然后合并在一起. [3]
| 特性 | XGBoost | LightGBM | 说明 |
|---|---|---|---|
| 决策树生长策略 | Level-wise (按层生长) | Leaf-wise (按叶子生长) | Leaf-wise 在分裂次数相同时能更快降低误差,获得更高精度,但更容易过拟合 |
| 切分点查找算法 | 预排序算法 | 直方图算法 | 直方图算法无需存储排序数据,内存消耗小,计算速度更快 |
| 并行策略 | 特征并行 & 数据并行 | 特征并行 & 数据并行 (优化) | LightGBM 采用 Reduce Scatter 机制,通信成本远低于 XGBoost |
| 类别特征处理 | 需手动编码 (如 One-Hot) | 可直接处理 | LightGBM 内置高效类别特征处理算法,无需手动编码且效果通常更好 |