1 概率无向图模型
1.1 定义
又称 Markov 随机场.
回顾图 由结点和边构成, 不考虑方向时为无向图. 概率图模型 是图表示的概率分布: 假设有概率分布 . 在图 中, 结点构成随机变量: ; 边表示随机变量之间的概率依赖关系. 接下来定义几个性质:
- 成对 Markov 性: 任意没有边连接的结点 , 对应随机变量 , 其他结点的集合记为 , 则有条件独立性:
- 局部 Markov 性: , 所有与 有边连接的结点记为 , 此外的所有结点记为 , 则 由于 , 因此当 , 等价于
- 全局 Markov 性: 假设一个集合 , 将 中的结点分开后取任意两个集合 , 则
这三个性质是等价的.
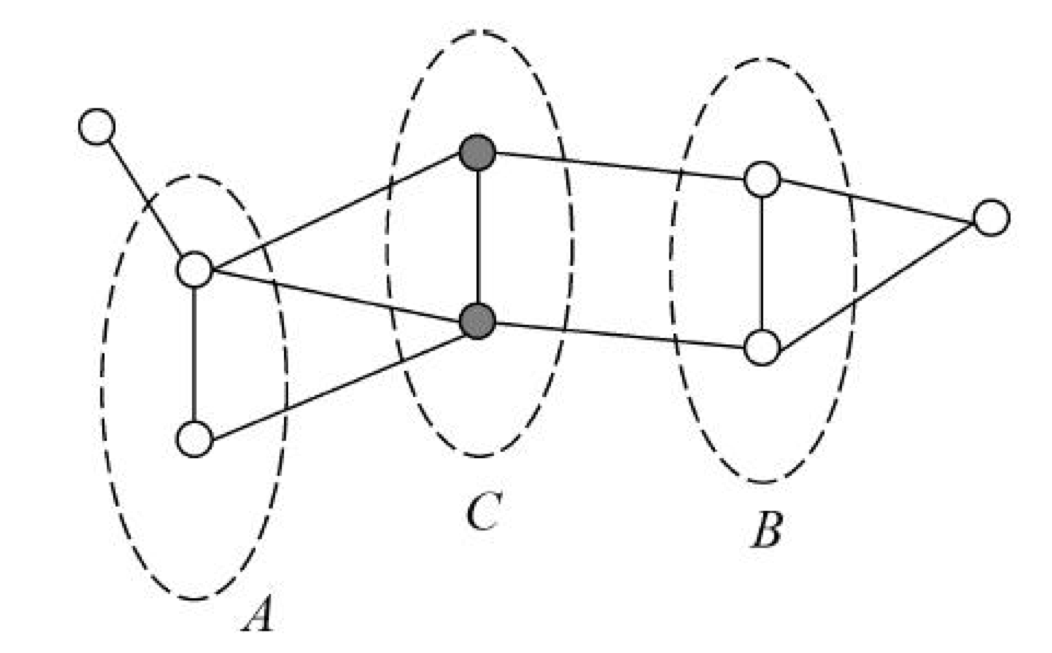
表示 , 且满足上述三个条件的任何一个.
1.2 因子分解
任何两个结点均有边连接的结点子集称为团; 如果一个团中不能再加进任何结点成为更大的团, 则它是最大团.
最大团显然不唯一, 也不代表元素个数要最多.
因子分解 (factorization) 就是把 表示成最大团上随机变量的函数的积的操作. 也即 这里 是规范化因子, 是势函数需要恒正, 例如 . 它的存在性由 Hammersley-Clifford 定理保证.
2 条件随机场
2.1 定义
随机变量 构成一个由 表示的 Markov 随机场, 即 (这里 表示与 连接的所有结点 ), 则称 为条件随机场.
我们主要考虑一类特别的图: 线性链. 即
定义对应的条件随机场:
满足
( 时只考虑单边)
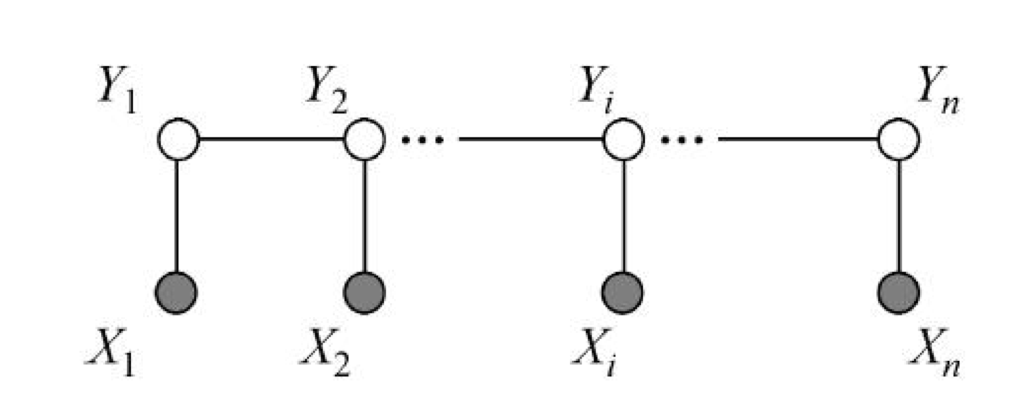
在标注问题中, 表示输入观测序列, 表示对应的输出标记序列.
2.2 参数化形式
对线性链条件随机场 进行因子分解:
当 , 其中 是规范化因子, 为对上述 exp 关于 求和. 是特征函数, 是对应权重.
另外, 这里的 是转移特征(因为项里面有 ), 是状态特征(因为只有 )
2.3 简化形式
假设有 个转移特征, 个状态特征, , 将 合并为
在所有位置 求和: 将系数 也统一表示为 . 因此 (2.1) 表示为
最后定义向量表示 , 则
2.4 矩阵形式
在标记序列 中额外加入 表示起始和终止状态. 基于上面的简化形式, 定义矩阵 其中
这样 是规范化因子 , 恰恰就是所有从 start 出发到 stop, 经过所有 的概率 之和.
如图, , 假设 , 各个位置的随机矩阵定义为 如图所示.
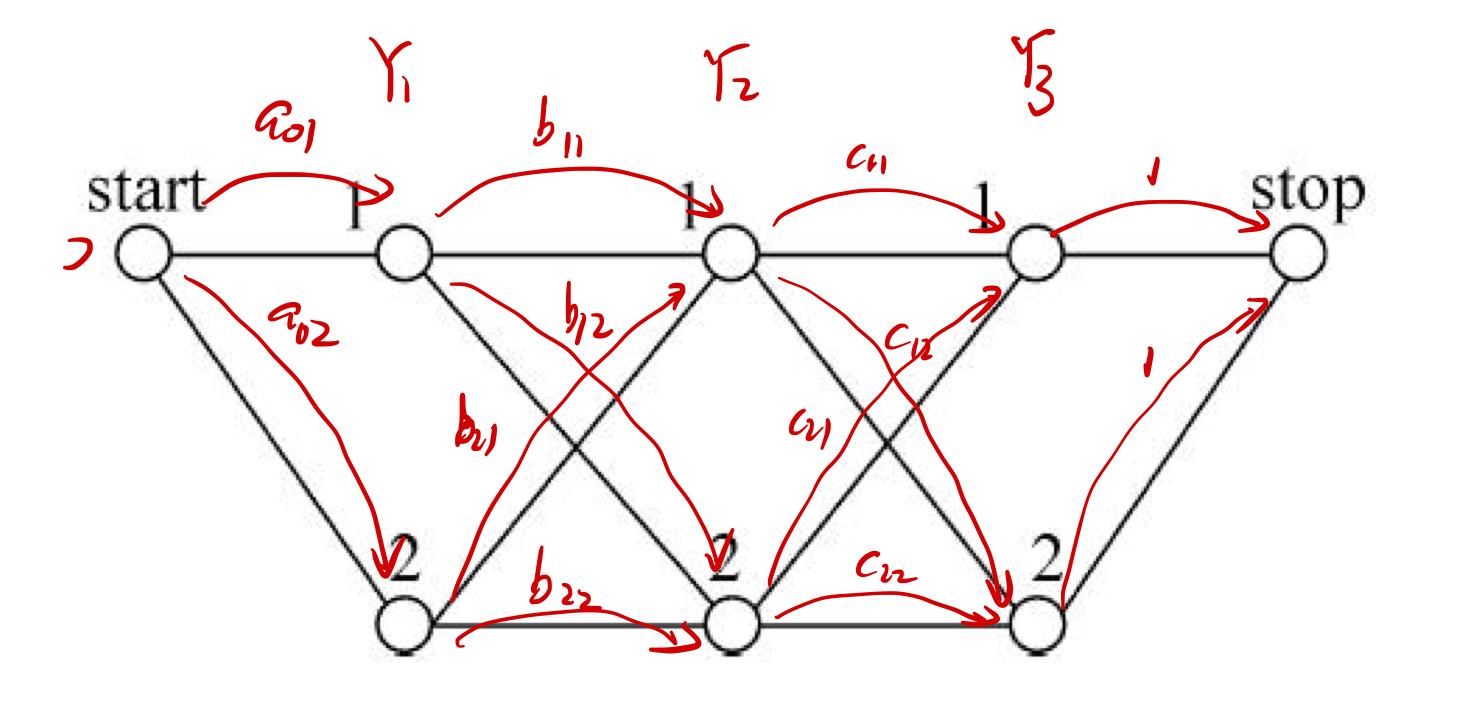
则 start 到 stop 的各路径的概率分别为 而计算 , 它的 位置的元素恰好是这个值.
3 概率计算问题
给定 , 输入 和输出 , 计算 以及相应的数学期望.
3.1 前向后向算法 概率计算
定义前向向量 然后定义 即
这里 表示从 1 走到 , 在位置 的标记是 ; ( 是 的可能取值个数) 的概率. 类似地定义后向向量
由此
其中 .
3.2 期望计算
首先计算特征函数 关于条件分布 的数学期望. 应用 (3.2):
假设经验分布为 , 则 关于 的期望为
4 学习算法
4.1 改进的迭代尺度法
假设我们根据训练集得到经验分布 , 则对数似然 而若 由因子分解式给出:
为了高效地道对数似然的极大值, 采用迭代的方法不断优化对数似然函数改变量的下界. 假设当前参数为 , 更新增量为 , 则需要求解以下方程(对转移和状态特征分别给出): 以及 这里 是 中出现的特征数总和
输入: 特征函数 , 经验分布
输出: 参数估计 和模型
- 取初值 .
- 对每一个 ,
- 若 , 是方程 的解;
- 若 , 是方程 的解, 这里 由 (4.3) 给出.
- .
- 如果不是所有 都收敛, 重复 2.
这里 对不同的 取值可能不同. 为此, 定义松弛特征 选取足够大的常数 使 恒成立, 则特征总数取 . 此时 (4.1) 变为 其中 同理有状态部分的方程改写, 其中
在上述算法中, 由于要取得足够大, 则 增大, 收敛变慢. 为此计算 (由前向后向递推公式看出). 此时更新方程进一步改写为 这里 , 可以用牛顿法求得 . 类似地
4.2 拟牛顿法
回顾模型 (2.2), 优化目标函数为 梯度函数为
参考 BFGS算法:
输入 特征函数 , 经验分布
输出
- 选定初始点 , 取正定对称矩阵 , .
- . 若 停止计算, 否则转 3.
- 由 求出 .
- 一维搜索: 求 使
- .
- . 若 停止计算, 否则 其中 , .
- , 跳转 3.
5 预测算法
给定 和输入序列 , 求条件概率最大的输出序列 . 注意到 等价于求解以下问题 其中 是局部特征向量.
输入 , 观测
输出 最优路径
- 初始化
- 对 :
- 终止:
- 返回路径 得到最优路径 .