9 注意力机制
1 注意力汇聚: Nadaraya-Watson 核回归
1.1 非参数注意力汇聚
我们想要学习数据集
例如, 定义 Gauss 核:
1.2
2 注意力评分函数
把上面的高斯核称为 (注意力)评分函数. 它会对输入加权, 最后用 softmax 归一化.
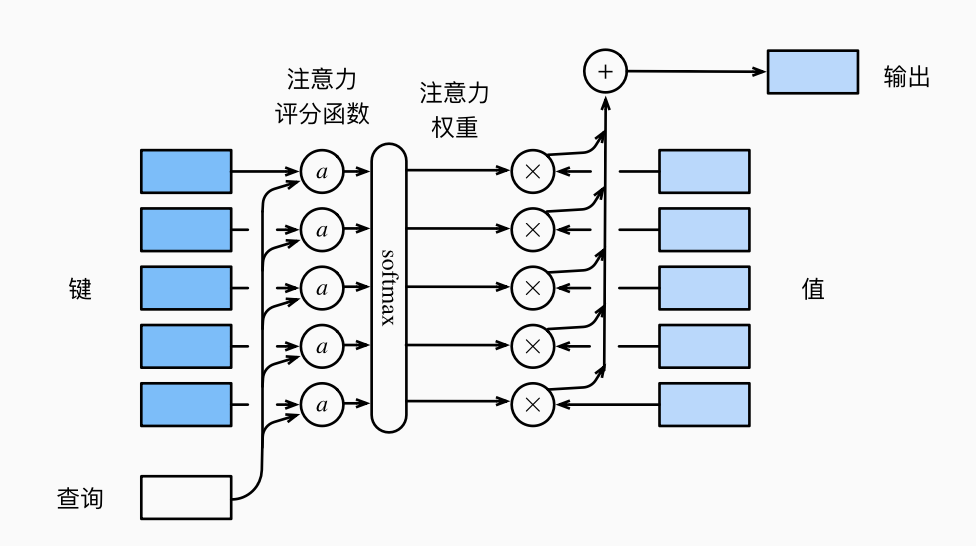
也即: 查询
2.1 掩蔽 softmax 操作
用来屏蔽没有意义的词元.
def masked_softmax(X, valid_lens):
"""通过在最后一个轴上掩蔽元素来执行softmax操作"""
#X:3D张量,valid_lens:1D或2D张量
if valid_lens is None:
return npx.softmax(X)
else:
shape = X.shape
if valid_lens.ndim == 1:
valid_lens = valid_lens.repeat(shape[1])
else:
valid_lens = valid_lens.reshape(-1)
#最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0
X = npx.sequence_mask(X.reshape(-1, shape[-1]), valid_lens, True,
value=-1e6, axis=1)
return npx.softmax(X).reshape(shape)
在超出我们定义的 valid_lens 部分用很大的负值替换, 使得 softmax 后为 0.
2.2 加性注意力
2.3 缩放点积注意力
点积计算效率更高, 但是要求
小批量版本, 有
3 Bahdanau 注意力
为了解决解码步骤使用和编码相同的上下文变量: 需要改变上下文变量.
3.1 模型
在 seq2seq 中, 我们把
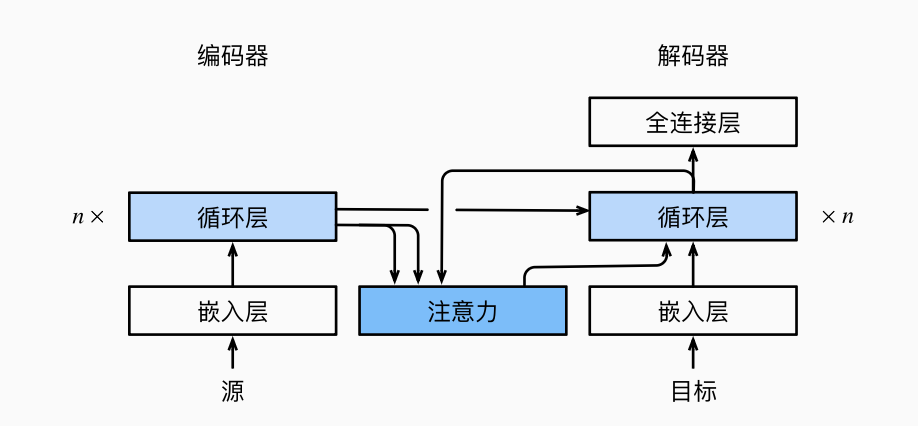
3.2 注意力编码器
4 多头注意力
用多组注意力汇聚来学习不同行为并进行连结.
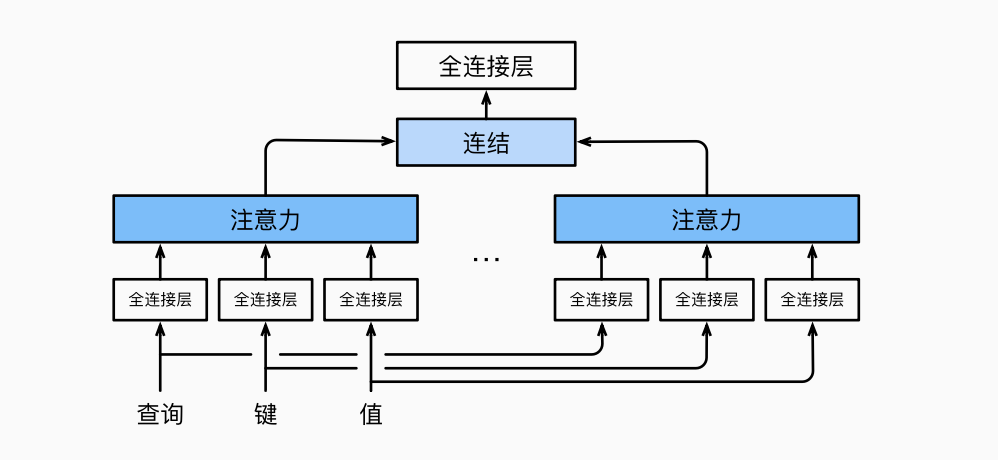
每一个注意力头
此外, 对多头注意力, 还需要线性转换
5 自注意力和位置编码
自注意力: 同一组词元同时充当查询、键、值, 也即每一个查询都会关注所有键值对生成一个注意力输出, 称为自注意力.
给定
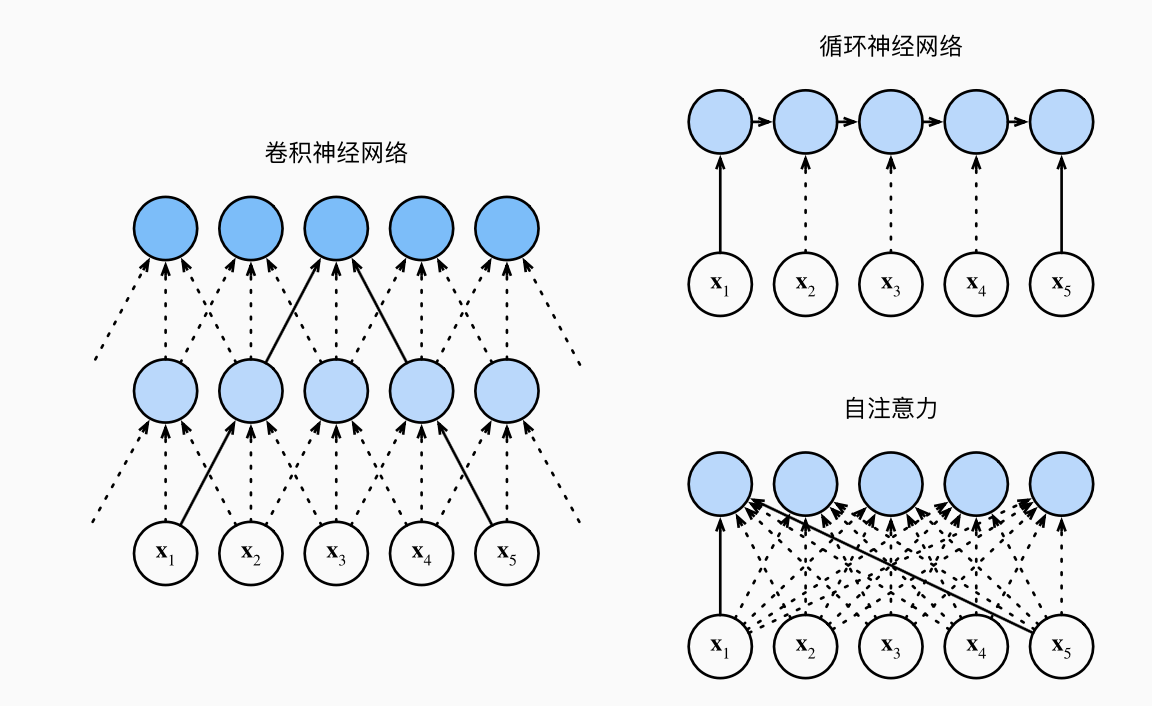
| 架构类型 | 计算复杂性 | 顺序操作数 | 最大路径长度 |
|---|---|---|---|
| 卷积神经网络 | 𝒪(kn·d²) | 𝒪(1) | 𝒪(n/k) |
| 循环神经网络 | 𝒪(n·d²) | 𝒪(n) | 𝒪(n) |
| 自注意力机制 | 𝒪(n²·d) | 𝒪(1) | 𝒪(1) |
5.1 位置编码
为了并行计算, 自注意力放弃了顺序操作, 改为添加位置编码, 对输入
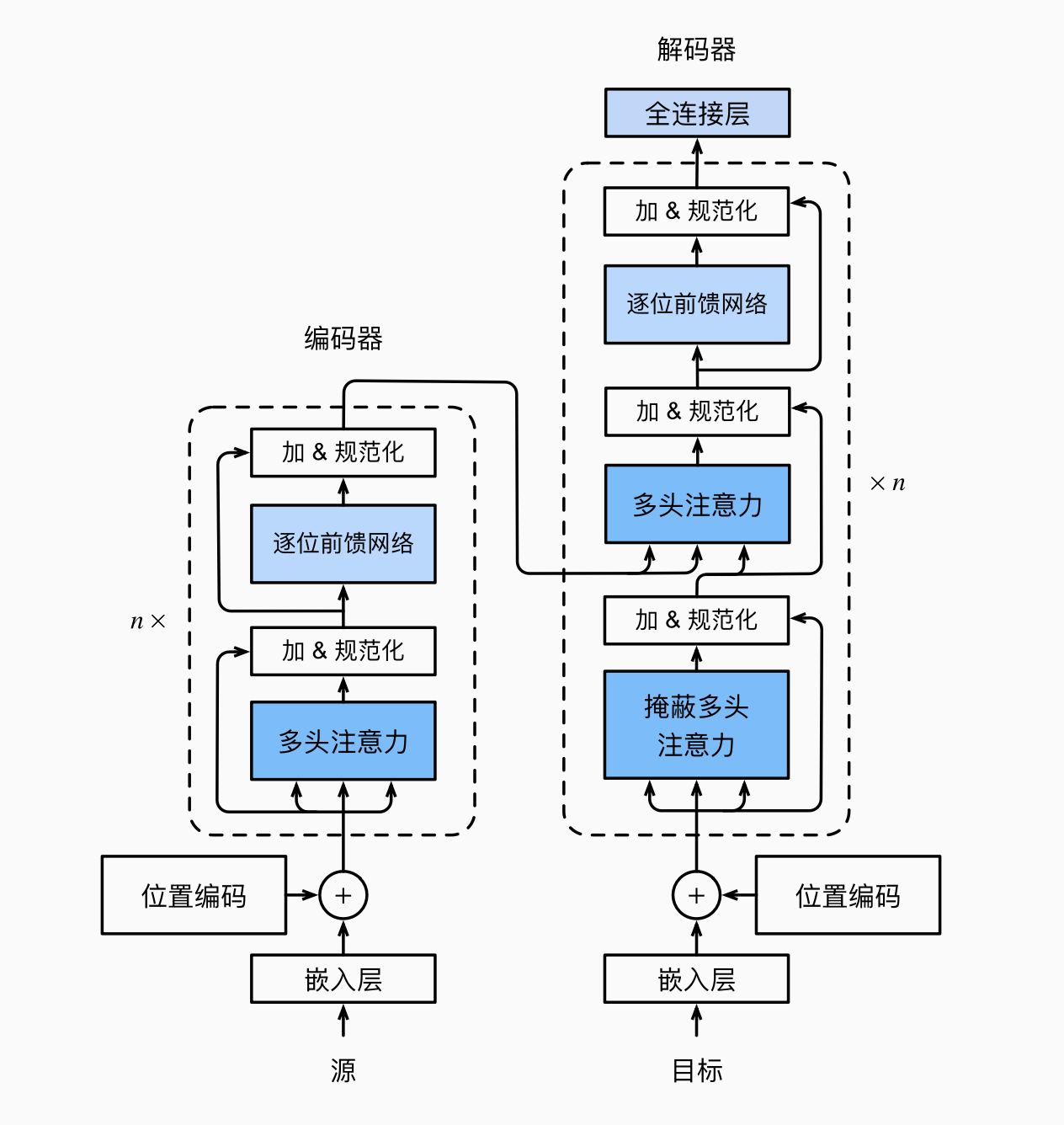
6 Transformer
class PositionWiseFFN(nn.Module):
"""基于位置的前馈网络"""
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,
**kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))