8 现代循环神经网络
1 门控循环单元 (GRU)
1.1 门控隐状态
门控循环单元用于控制何时更新隐状态.
1.1.1 重置门 更新门
重置门允许我们控制“可能还想记住”的过去状态的数量;
更新门允许我们控制新状态中有多少个是旧状态的副本.
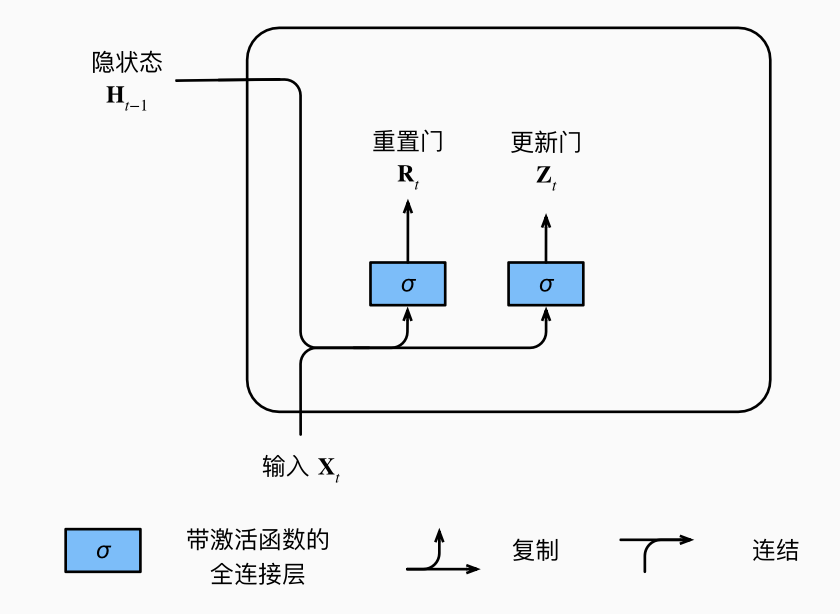
这里
1.1.2 候选隐状态
将重置门
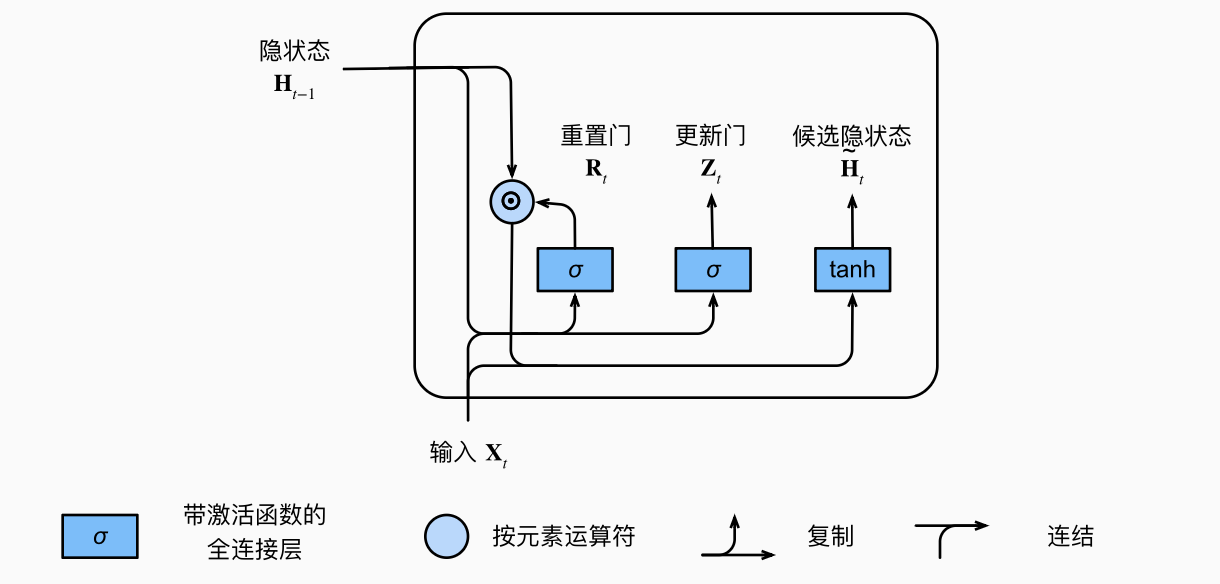
1.1.3 隐状态
有了
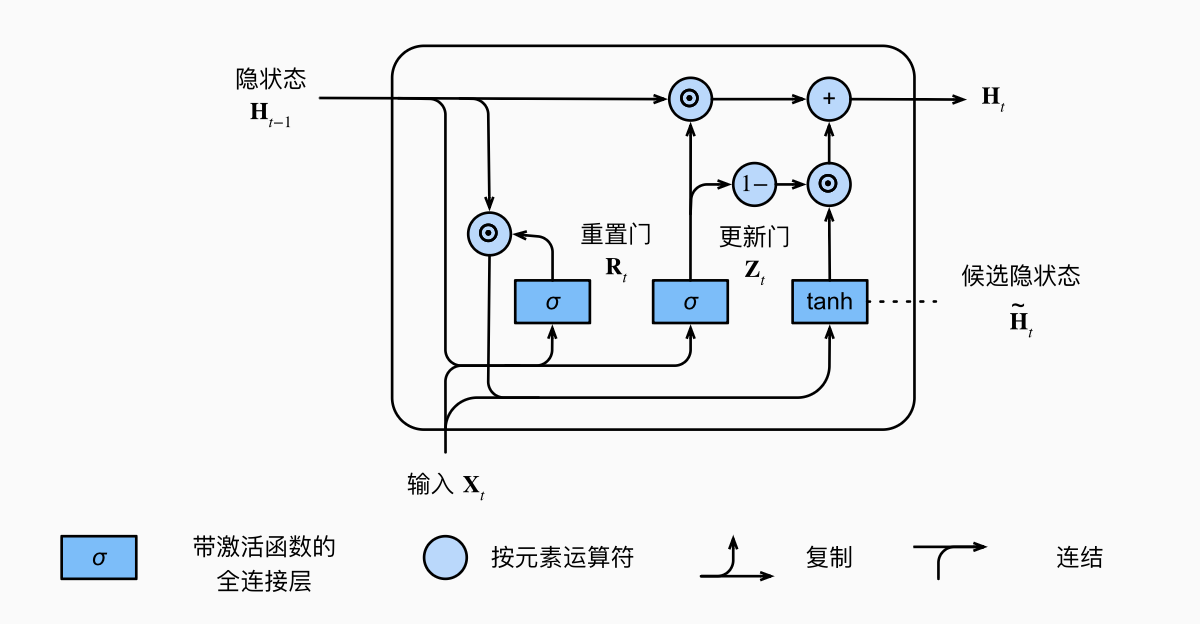
1.2 从零实现
数据集导入, 同上一篇笔记:
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
1.2.1 初始化参数
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xz, W_hz, b_z = three() # 更新门参数
W_xr, W_hr, b_r = three() # 重置门参数
W_xh, W_hh, b_h = three() # 候选隐状态参数
#输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
#附加梯度
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
1.2.2 模型
def init_gru_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device))
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = H @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
1.3 简洁实现
num_inputs = vocab_size
gru_layer = nn.GRU(num_inputs, num_hiddens)
2 长短期记忆网络 (LSTM)
引入长期记忆
2.1 门控记忆元
2.1.1 输入门 输出门 遗忘门
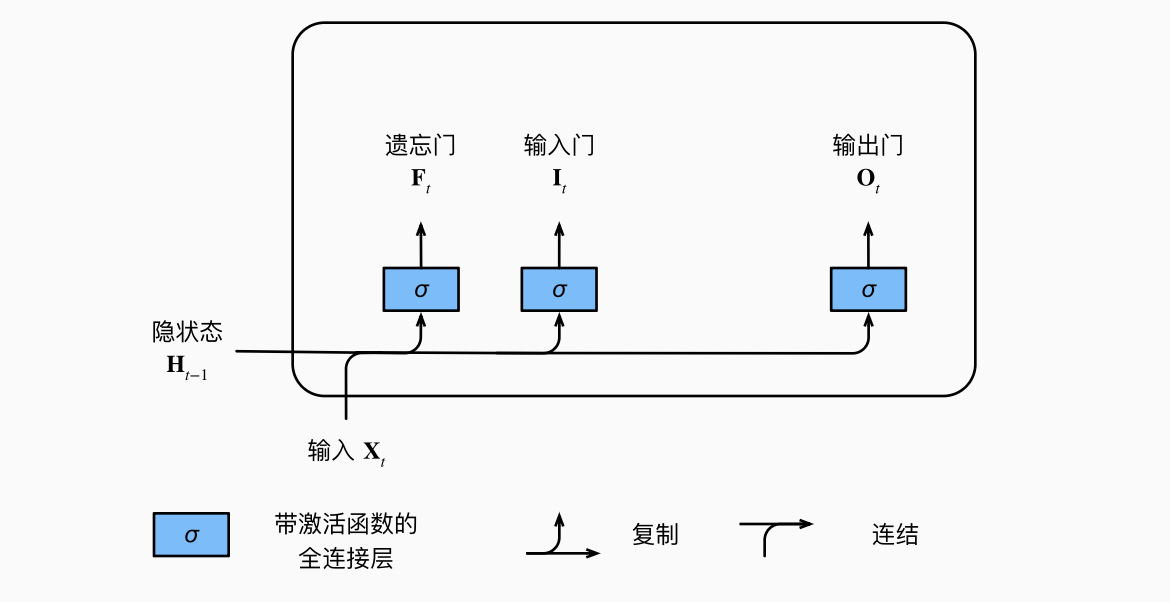
假设有
这里
2.1.2 候选记忆元
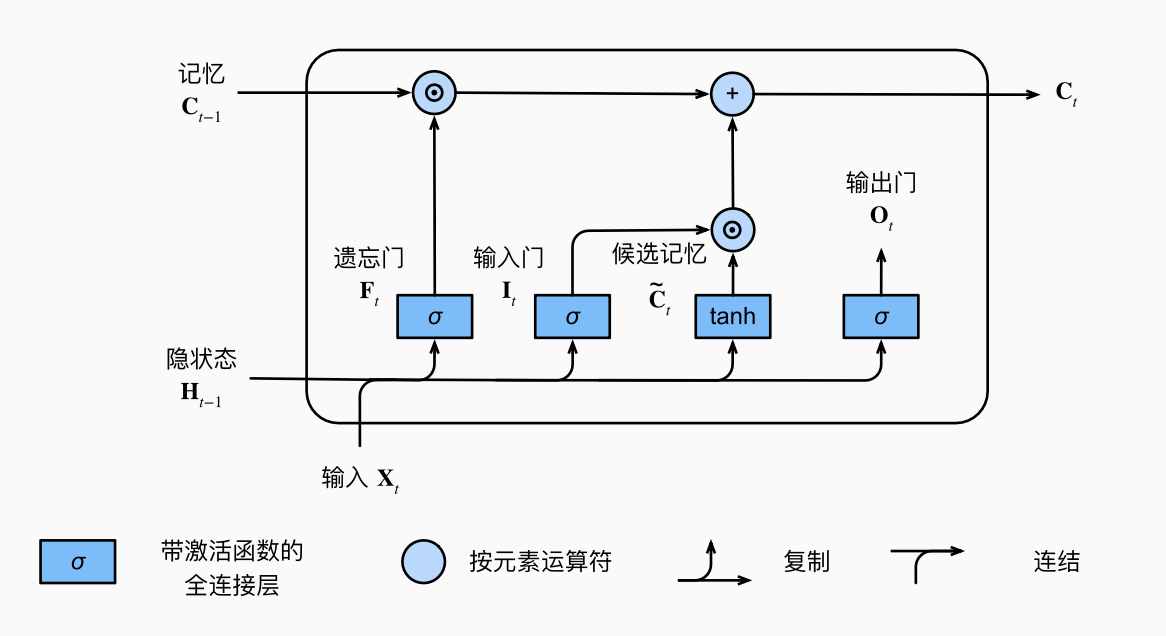
2.1.4 隐状态
输出门会根据长期记忆决定输出的内容:
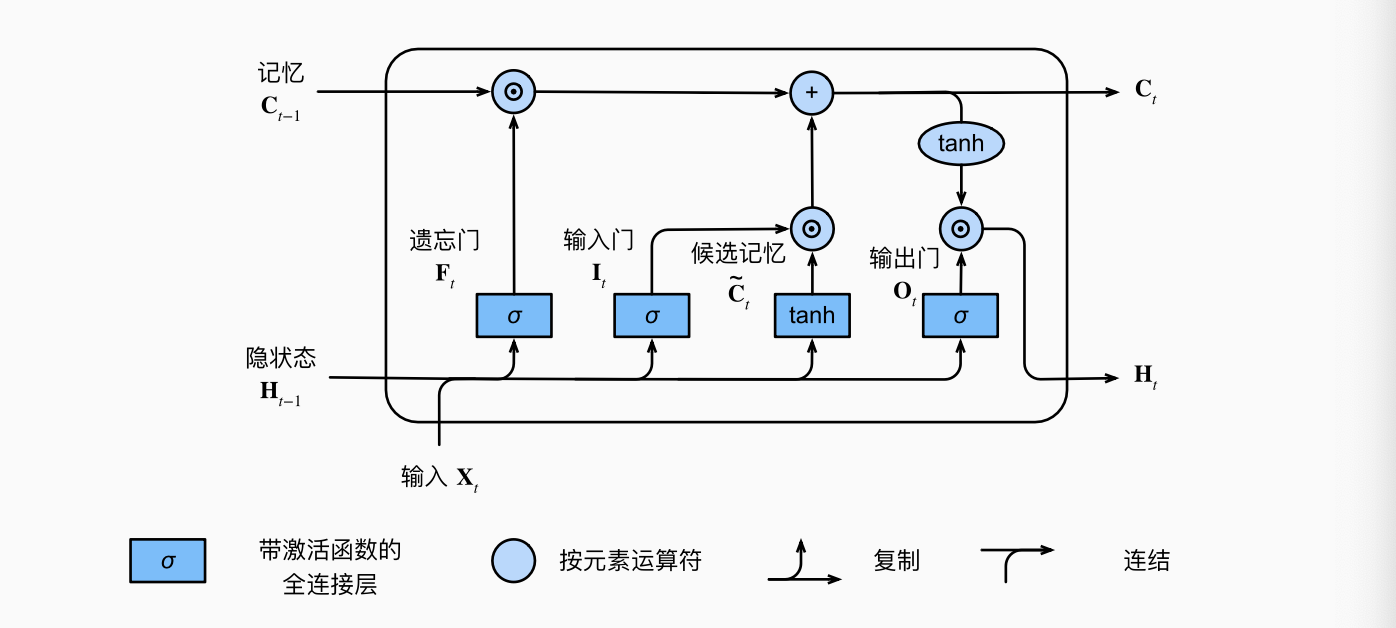
这就是完整版的 LSTM.
3 深度循环神经网络
4 双向循环神经网络
有些时候词语会和前后文都有关系.
4.1 隐 Markov 模型中的动态规划
假设
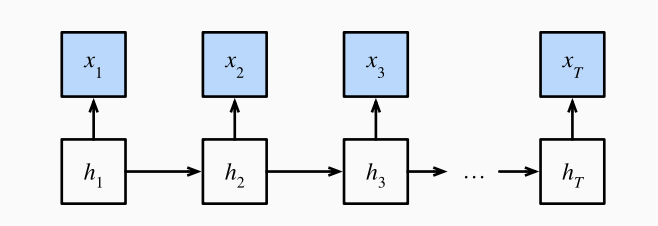
因此我们有联合概率分布
现在假设我们观测到除了
同样地有向后递归:
因此后向递归为
这样即使遍历了所有可能的
双向模型
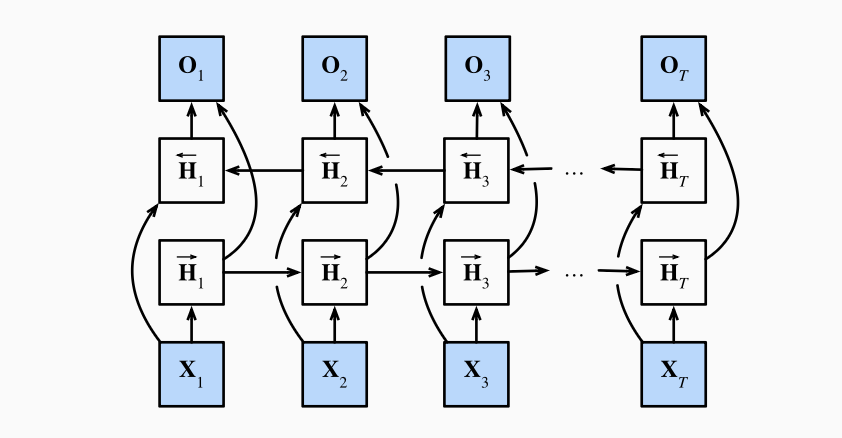
添加了反向传递信息的隐藏层. 在时间
输出层:
双向网络在预测输出方面会有很大的性能下降, 因此只会用于填充缺失单词、词元注释等.
双向网络有很大的计算开销: 需要同时前后向计算, 且两者互相依赖.
机器翻译 数据集
编码器 解码器
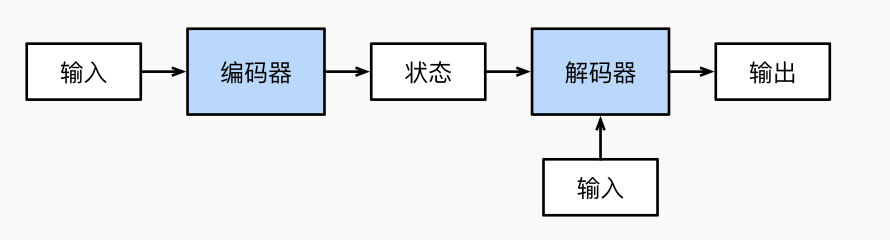
我们需要一个编码器, 接受长度可变的序列, 输出固定形状的编码状态; 还需要一个解码器, 接受固定形状的编码状态, 输出长度可变的序列.
编码器
class Encoder(nn.Module):
"""编码器-解码器架构的基本编码器接口"""
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedError
解码器
class Decoder(nn.Module):
"""编码器-解码器架构的基本解码器接口"""
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def forward(self, X, state):
raise NotImplementedError
合并两者
class EncoderDecoder(nn.Module):
"""编码器-解码器架构的基类"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)
序列到序列学习 (Seq2seq)
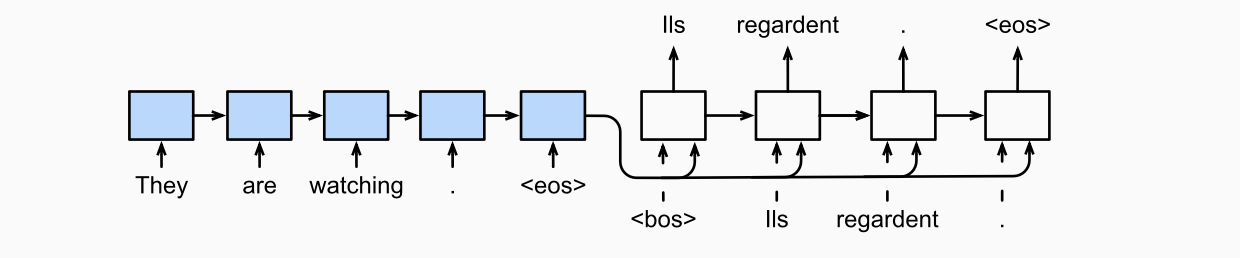
编码器
考虑一个 1 批量大小的序列样本:
这里加入嵌入层 (embedding) 来获取词元的特征向量, 嵌入层是一个 vocab_size x embed_size 的矩阵.
class Seq2SeqEncoder(d2l.Encoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
#嵌入层
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers,
dropout=dropout)
def forward(self, X, *args):
#输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X)
#在循环神经网络模型中,第一个轴对应于时间步
X = X.permute(1, 0, 2)
#如果未提及状态,则默认为0
output, state = self.rnn(X)
#output的形状:(num_steps,batch_size,num_hiddens)
#state的形状:(num_layers,batch_size,num_hiddens)
return output, state
encoder = Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
encoder.eval()
X = torch.zeros((4, 7), dtype=torch.long)
output, state = encoder(X)
output.shape
解码器
解码器学习
class Seq2SeqDecoder(d2l.Decoder):
"""用于序列到序列学习的循环神经网络解码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
def forward(self, X, state):
#输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X).permute(1, 0, 2)
#广播context,使其具有与X相同的num_steps
context = state[-1].repeat(X.shape[0], 1, 1)
X_and_context = torch.cat((X, context), 2)
output, state = self.rnn(X_and_context, state)
output = self.dense(output).permute(1, 0, 2)
#output的形状:(batch_size,num_steps,vocab_size)
#state的形状:(num_layers,batch_size,num_hiddens)
return output, state
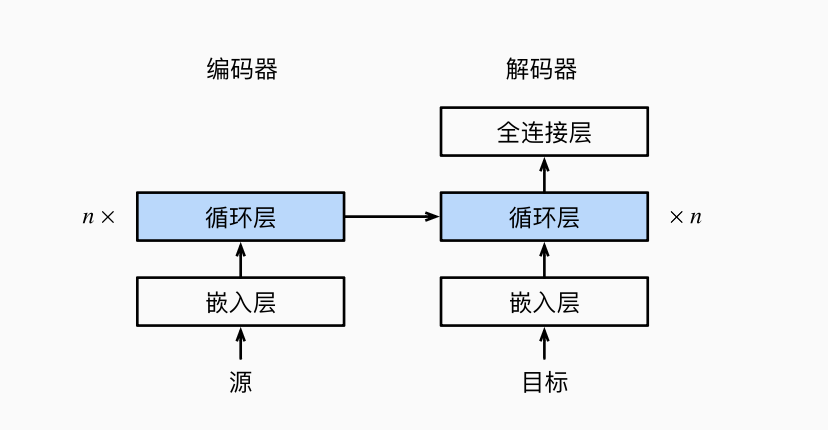
使用 softmax 获得分布, 计算交叉熵损失函数来进行优化. 通过我们定义的 sequence_mask 函数, 将不相关的项屏蔽为 0:
def sequence_mask(X, valid_len, value=0):
"""在序列中屏蔽不相关的项"""
maxlen = X.size(1)
mask = torch.arange((maxlen), dtype=torch.float32,
device=X.device)[None, :] < valid_len[:, None]
X[~mask] = value
return X
X = torch.tensor([[1, 2, 3], [4, 5, 6]])
sequence_mask(X, torch.tensor([1, 2]))
...
评估
BLEU (Bilingual evaluation understudy) 对于预测序列的
定义
束搜索
我们的目标是从所有可能的输出子序列 (
贪心搜索
每一个时间步
它的问题是局部最优的组合不一定是全局最优.
穷举搜索 (略)
束搜索
束搜索 (beam search) 是两者的中间版本. 定义超参数束宽
- 在时间步 1, 找有最高条件概率的
个词元( 个输出选项的第一个词元). - 此后的每一步, 基于上次的
歌候选序列, 从 个选择中继续选出最高的 个.
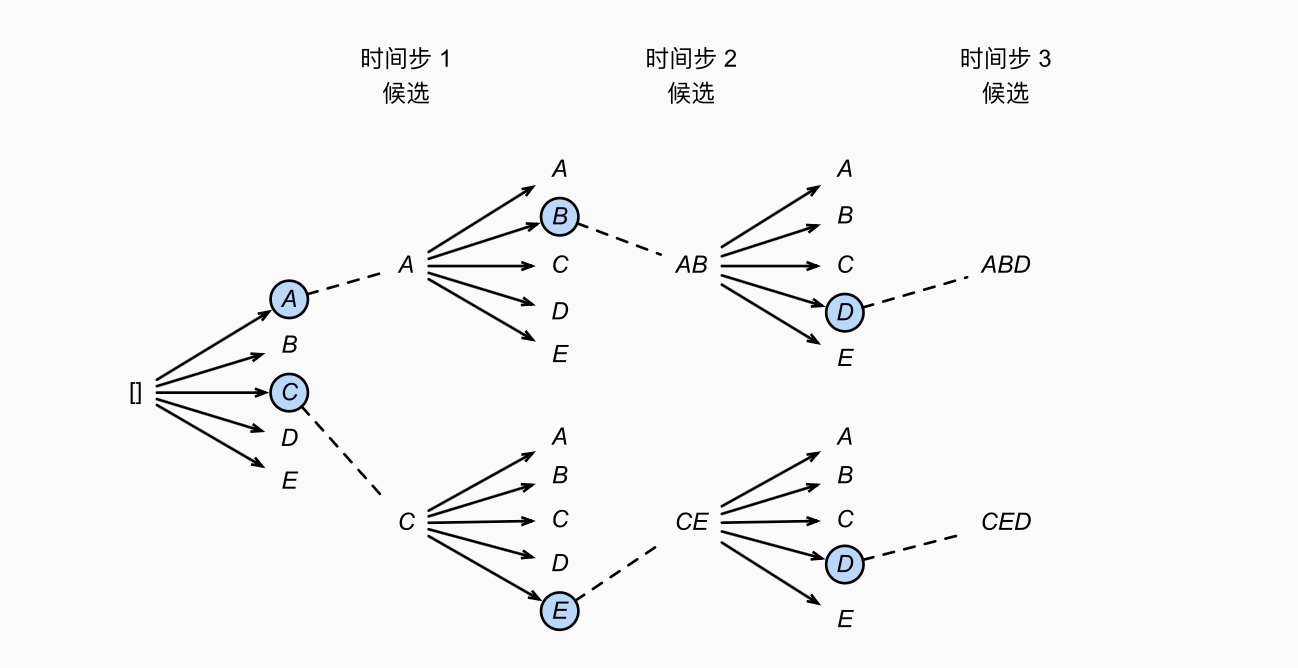
复杂度