Select a result to preview
3 多层感知机非常适合处理表格数据. 但是如果是一张图片, 每个像素作为一个参数, 那参数量超乎寻常. 此外, 对于图像识别, 我们需要一些额外的要求:
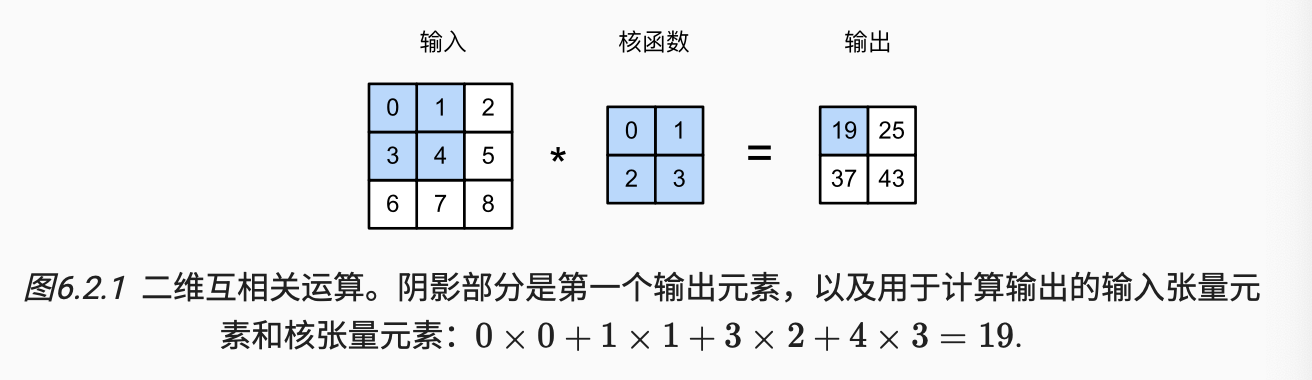
记多层感知机的输入为二维图像
(进行了下标的替换).
因此,
(1.1) 称为一个卷积层,
在数学上, 两个函数 (
图像的每个像素都包含了三个通道 (RGB), 因此图像实际上是一个三维张量 (例如
因此,
为了更好的支持输入
暂时忽略通道, 只考虑二维图像.
想象一个卷积核在输入上到处扫描, 由于边界的影响, 输出尺寸会略小于输入尺寸. 如果输入为
import torch
from torch import nn
def corr2d(X, K):
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i+h, j:j+w] * K).sum()
return Y
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super().__init__()
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias
对于一张 (二维) 黑白图像:
tensor([[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.]])
tensor([[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.]])
这个核只能检测垂直边缘.
对于更复杂的卷积核, 如何不靠手动来设计滤波器?我们通过输入输出、梯度下降来进行学习.
conv2d = nn.Conv2d(1,1, kernel_size=(1,2), bias=False)
#一个二维卷积层, 有1个输出通道, 有形状为(1,2)的卷积核
X = X.reshape((1, 1, 6, 8)) #批量大小, 通道, 高度, 宽度
Y = Y.reshape((1, 1, 6, 7))
lr = 3e-2 #learning rate
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat - Y) ** 2
conv2d.zero_grad()
l.sum().backward()
conv2d.weight.data[:] -= lr * conv2d.weight.grad
if (i+1) % 2 == 0:
print(f'epoch {i+1}, loss {l.sum():.3f}')
为了解决卷积丢失像素的问题, 我们可以在输入的边缘填充一些 0. 假设填充的行、列卫
很多时候为了输入输出相同, 设置
如果
是奇数, 在高度两侧填充 行; 否则, 可以考虑一侧 , 另一侧 . 因此一般卷积核的尺寸都会选择奇数.
而如果每次移动的步幅不为 1, 也会影响输出的尺寸. 假设垂直步幅为
当图像有多个通道, 卷积核也需要有多个通道, 他们分别进行卷积运算, 然后对通道求和得到二维张量.
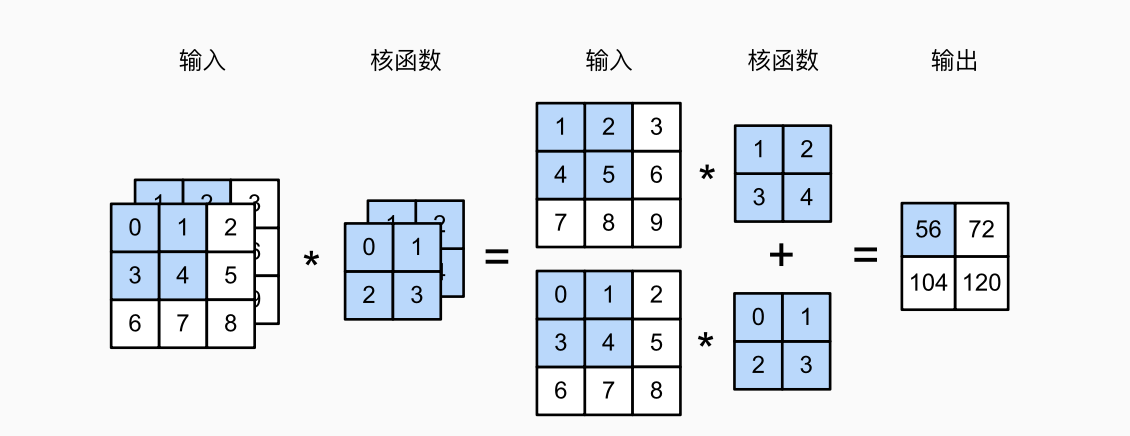
def corr2d_multi_in(X, K):
return sum(corr2d(x, k) for x, k in zip(X, K))
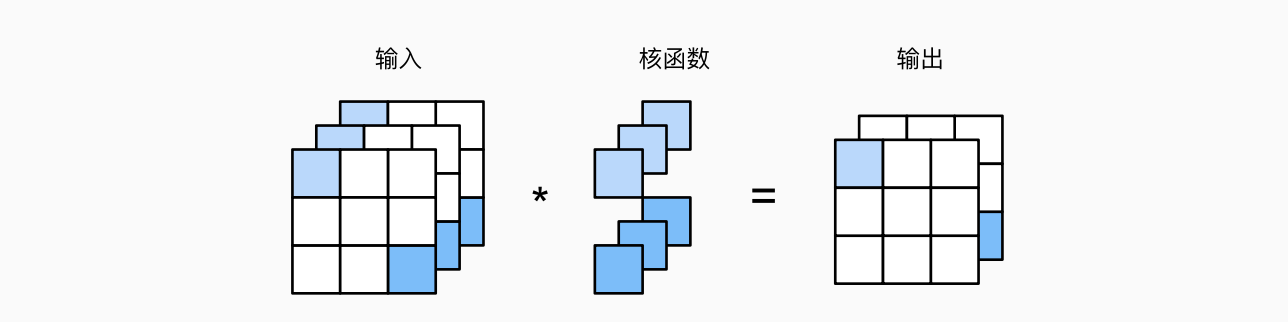
输入、输出通道分别为
def corr2d_multi_in_out(X, K):
return torch.stack([corr2d_multi_in(X, k) for k in K], 0)
#对第0个维度迭代
它的唯一计算发生在通道上.
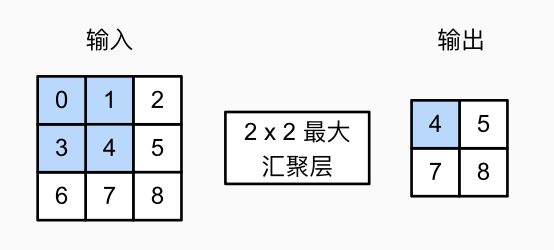
在卷积层我们学习了图像的局部特征, 现在通过 汇聚层(pooling,池化层) 将各种信息汇总到图像整体上.
以最大汇聚层为例. 事实上它们和卷积类似, 但是操作是确定性的(取最大值, 或者平均值), 不依赖卷积核之类的具体参数.
同样有填充和步幅.
汇聚层只会在每个通道单独运算, 不会对通道进行汇总, 因此输入输出的通道数相同.
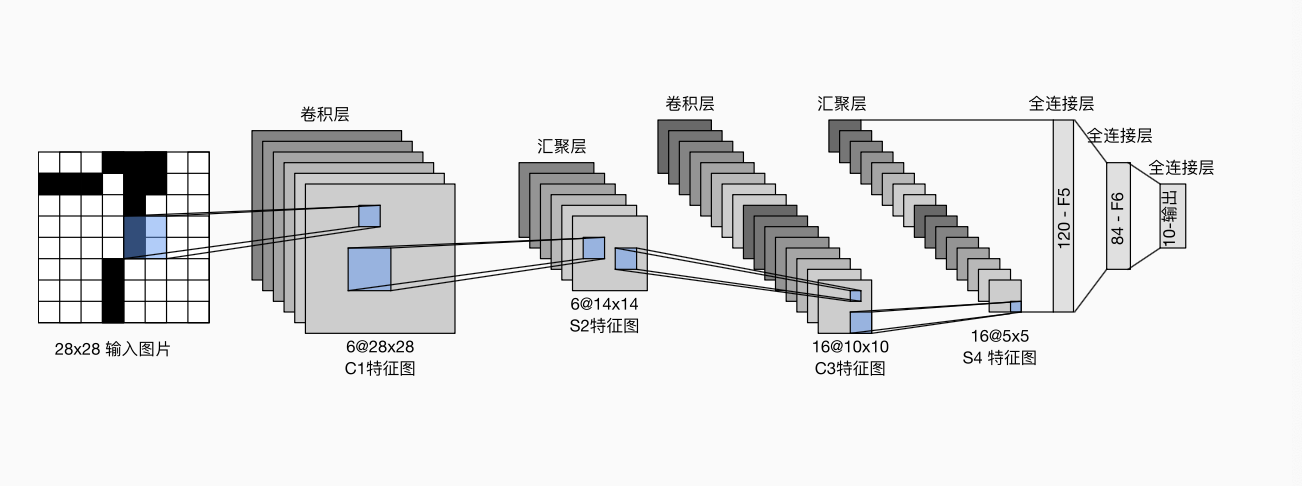
也即:
net = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2), #池化层
nn.Conv2d(6, 16, kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16*5*5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84, 10)
)