3 多层感知机
1 多层感知机
线形的假设是很强的, 很多时候也不能拟合所有关系. 为此, 可以在网络中加入更多的层, 来拟合更加复杂的关系.
1.1 隐藏层
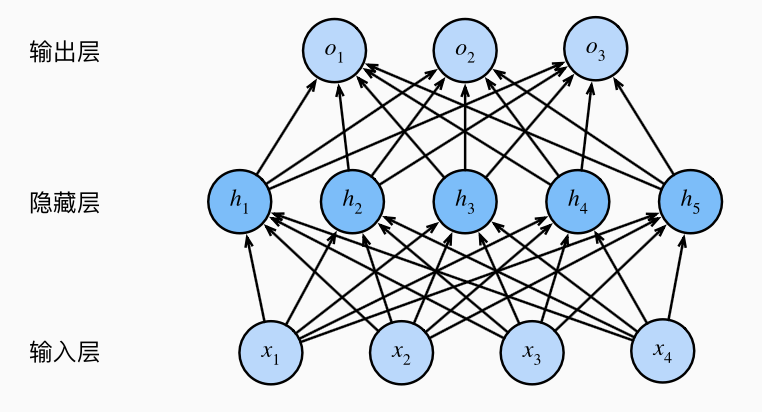
我们同样假设
但事实上, 这和单层没有任何区别:
因此只要取
为了实现不平凡的多层效果, 需要添加非线性的激活函数
1.2 激活函数
1.2.1 ReLU 函数
可以用 y = torch.relu(x) 来计算. 在输入值精确等于 0 时, 导数规定使用左导数 0.
ReLU 有一些变体, 例如 pReLU (参数化 ReLU):
1.2.2 Sigmoid 函数
它会将值映射到
1.2.3 tanh 函数
2 模型选择 欠拟合 过拟合
3 权重衰减/L2 正则化
在原先的损失函数
3.1 从零实现
3.2 简洁实现
4 暂退法 (Dropout)
4.1 流程
在多层神经网络中, 我们在训练过程中随机丢弃一些神经元(在训练过程的每一次迭代中, 在计算下一层前将当前层的一些节点清零).
对于剩下未被丢弃的节点, 进行规范化(normalization), 来消除偏差, 也即以概率
例如, 我们在下面的隐藏层删除了
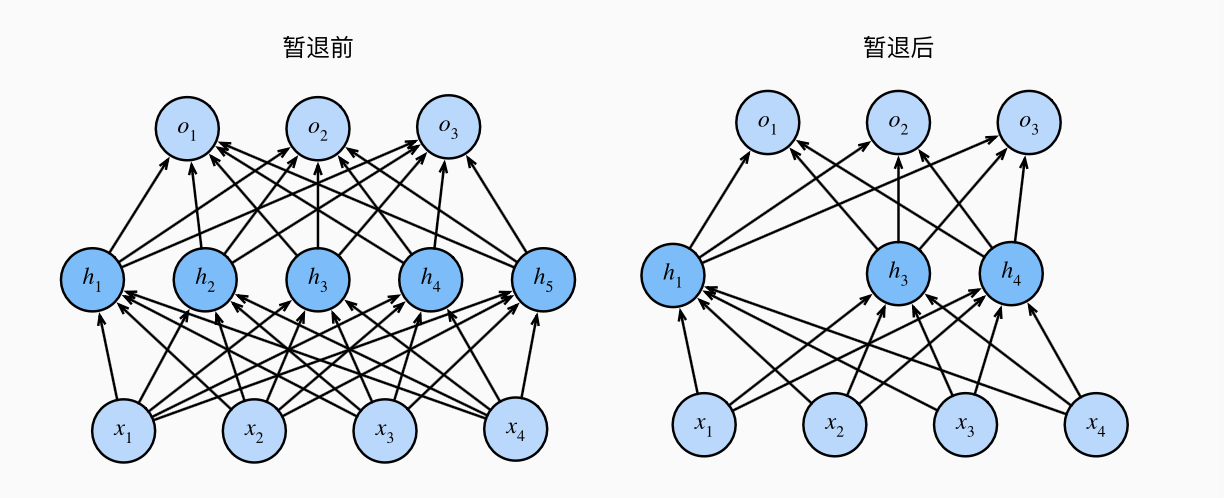
然而在测试时, 所有被 dropout 的值都会参与计算. (测试时 dropout 不参与计算的情形, 仅用于测试网络的稳定性)
4.2 从零实现
import torch
from torch import nn
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
if dropout == 1:
return torch.zeros_like(X)
if dropout == 0:
return X
mask = (torch.rand(X.shape) > dropout).float()
return mask * X / (1.0 - dropout)
通常在靠近输入层的地方我们设置较低的 dropout 概率.
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2, is_training=True)
super(Net, self).__init__()
self.self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
if self.training == True:
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
4.3 简洁实现
net = nn.Sequential(nn.Flatten(),
nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(dropout1),
nn.Linear(256, 256),
nn.ReLU(),
nn.Dropout(dropout2),
nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
5 前向传播 反向传播 计算图
5.1 前向传播
前向传播 (forward propagation/pass), 就是指按顺序计算输出的值. 例如, 我们有一个隐藏层(不包含偏置项), 一个激活层, 一个输出层, 输入为
我们可以计算带正则项的损失函数
上述流程可以用计算图来表示:
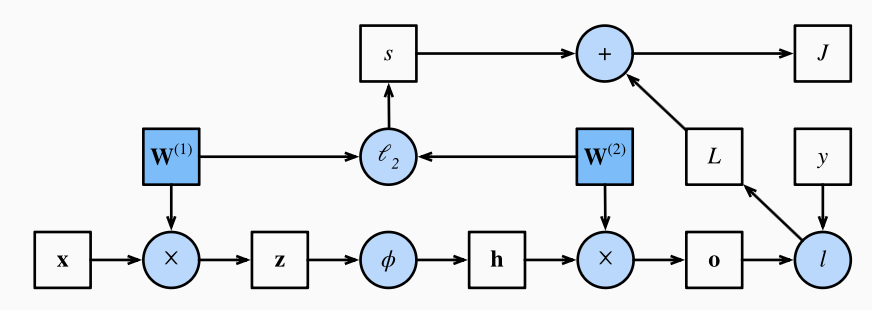
5.2 反向传播
反向传播是计算参数梯度来更新参数. 需要使用链式法则. 一般地, 给定
对于上面的例子, 首先
回到输出层
进而到隐藏层
最后输入层:
6 梯度稳定性和模型初始化
6.1 梯度消失与梯度爆炸
6.2 参数初始化: Xavier 初始化
这里不讨论随机正态分布初始化这种做法, 尽管它效果一般来说很有效.
首先考虑没有非线性的全连接层输出: