2 线性神经网络
本部分也是笔记库中常见的话题了, 可以参考 1 Linear Regression & Logistic Regression, 1 Simple Linear Regression, 1 Regression & Classification. 本篇会更加侧重代码的实现.
1 线性回归
1.1 随机梯度下降
为了优化梯度下降每次都要遍历整个数据集的低效, 我们提出小批量随机梯度下降 (minibatch stochastic gradient descent)
每次迭代中, 我们随机抽样一个小批量
注意, 根据我们对损失函数的定义
这里
同样我们需要避免使用 for 循环而是使用线性代数的方法进行计算. 向量的加法, 耗时远小于逐元素运算.
1.2 最大似然估计
回顾一下最小二乘等价于最大似然估计的推导. 假设噪声项
1.3 线性回归到深度网络
我们用如下图示来重新表示线性回归模型:
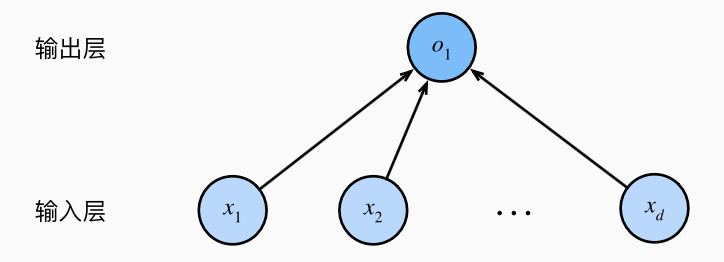
因此线性回归是一个单层神经网络. (我们只考虑计算, 因此在数层数的时候, 这里忽略输入层).
这里每一个输入都和每一个输出 (这里只有一个输出) 相连接, 称它为全连接层.
2 线性回归的实现
import random
import torch
%matplotlib inline
2.1 生成数据集
def synthetic_data(w, b, num_examples):
X = torch.normal(0, 1, (num_examples, len(w)))#N(0,1), 且定义了X的尺寸
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
回忆 torch.mm, 它只能进行 2D 矩阵的乘法, 而这里的
torch.matmul更加灵活.
图像大概是:
2.2 读取数据集
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices) #保证读入顺序的随机性
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(indices[i:min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]
yield是一种生成器函数, 是懒加载的机制. 函数运行到yield时返回值, 并暂时停止. 下次调用时, 从停止的地方继续运行. 例如:def data_iter(): print(1) yield 'a' print(2) yield 'b' a = data_iter() #此时无事发生 b = next(a) #1 , 因为执行了函数 b #'a', 因为yield的值传到了b里 b = next(a) #2 , 从上次的地方继续执行 b #'b'
2.3 初始化模型参数
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
2.4 模型相关定义
模型
def linreg(X, w, b):
return torch.matmul(X, w) + b
损失函数
def squared_loss(y_hat, y):
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
定义优化算法
def sgd(params, lr, batch_size):
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()
在
with torch.no_grad():块内,所有张量的.requires_grad都默认为 False
• 自动关闭 autograd 引擎(autograd engine)
• 节省显存和计算资源
• 加快推理速度
• 避免不必要的梯度跟踪
2.5 训练
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y)
l.sum().backward()
sgd([w, b], lr, batch_size) #使用参数的梯度进行更新
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch+1}, loss {float(train_l.mean()):f}')
结果评估:
print(f'w误差: {true_w - w.reshape(true_w.shape)}')
print(f'b误差: {true_b - b}')
3 简洁实现
3.1 读取数据集
可以用 DataLoader 实现数据读取:
from torch.utils import data
def load_array(data_arrays, batch_size, is_train=True):
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
batch_size = 10
data_iter = load_array((features, labels), batch_size)
data_iter 的使用和前面相同. 读取的方式略有不同:
next(iter(data_iter))
3.2 定义模型
from torch import nn #neural network
net = nn.Sequential(nn.Linear(2, 1))
这里 2 是我们的输入特征形状 (2 维), 1 是我们的输出形状 (1 维)
3.3 初始化模型参数
我们可以直接访问 net 并进行修改
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
3.4 模型相关定义
loss = nn.MSELoss()
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
3.5 训练
num_epochs = 3
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X), y)
trainer.zero_grad()
l.backward()
trainer.step()
l = loss(net(features), labels)
print(f'epoch {epoch+1}, loss {l:f}')
评估
w = net[0].weight.data
b = net[0].bias.data
4 Logistic 回归
4.1 独热编码
在分类问题中, 我们可以用 one-hot encoding 来保证类别的编码不和类别的自然顺序有关. 例如, 有三个类
4.2 网络架构
假设我们有四个特征
假设我们依然用线性模型来进行预测:
可以简单表示为
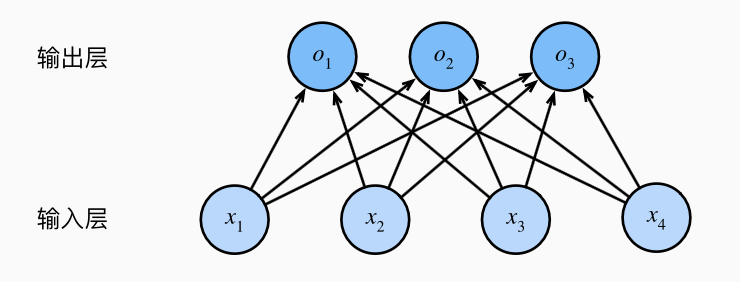
关于参数开销: 给定
个输入和 个输出的全连接层, 参数开销为 . 但是 Zhang et al., 2021 指出开销可以缩减到任意 .
为了让输出的值规范化(作为概率, 方便进行预测类别), 我们使用softmax函数:
这会变成 0-1 的值, 并且和为 1. 大小关系依然保持, 也即
4.3 小批量样本的矢量化
假设一个批量的样本
由于中的每一行代表一个数据样本, 那么softmax运算可以按行(rowwise)执行: 对于
4.4 最大似然估计
类似地, 使用最大似然估计:
我们称这个函数为交叉熵损失 (cross-entropy loss).
注意到
关于熵, 可以参考 4 Jensen's Inequality, Entropy.