10 生成对抗网络 GAN
1 主要架构
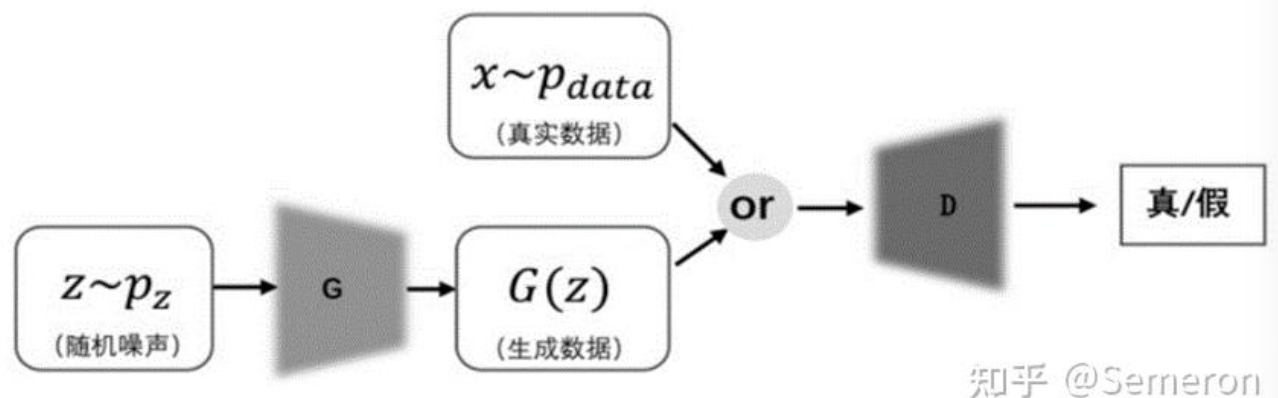
GAN 主要包含 生成器 和 判别器. 生成器基于随机噪声生成数据, 判别器用来判断它和真实数据哪个是真的.
生成器的目的是尽可能生成真实的数据, 判别器的目标是尽量判别真伪, 他们的目标截然相反, 会促使两个网络性能都有所提高.
2 损失函数的理论推导
损失函数需要满足:
- 判别器尽可能找出两种数据分布的不同点
- 生成器要让生成数据的分布与真实数据完全一样
设真实分布为
这里
从流程上看,
- 首先固定
, 求解令损失函数最大的 (优化判别器) - 然后固定
, 求解令损失函数最小的 (优化生成器)
2.1 第一步
对
(事实上
(回顾 KL散度 和 JS散度)
2.2 第二步
因此, 最后的损失函数就是两者的 JS 散度!
2.3 存在问题
我们展开 JS 散度的表达式:
若两个分布没有重叠, 例如
这容易造成梯度消失!
3 损失函数的具体计算方法
由于我们用神经网络拟合概率分布, 生成的是具体的样本点, 因此将期望替换为均值:
4 PyTorch 实现
4.1 判别器
class Discriminator(nn.Module):
def __init__(self,in_features=784):
"""in_features : 真实数据的维度、同时也是生成的假数据的"""
super().__init__()
self.disc = nn.Sequential(nn.Linear(in_features,128),
nn.LeakyReLU(0.1), #由于生成对抗网络的损失非常容易梯度消失,因此使用LeakyReLU
nn.Linear(128,1), nn.Sigmoid()
)
def forward(self,data):
"""输入的data可以是真实数据时,Disc输出dx。输入的data是gz时,Disc输出dgz"""
return self.disc(data)
4.2 生成器
class Generator(nn.Module):
def __init__(self,in_features,out_features=784):
"""
in_features:生成器的in_features,一般输入z的维度z_dim,该值可自定义
out_features:生成器的out_features,需要与真实数据的维度一致
"""
super().__init__()
self.gen = nn.Sequential(nn.Linear(in_features,256)
#,nn.BatchNorm1d(256)
,nn.LeakyReLU(0.1)
,nn.Linear(256,out_features)
,nn.Tanh() #用于归一化数据
)
def forward(self,z):
gz = self.gen(z)
return gz
4.3 损失函数 优化器
#实例化判别器与生成器
z_dim = 64
realdata_dim=784
gen = Generator(in_features=z_dim,out_features=realdata_dim).to(device)
disc = Discriminator(in_features=realdata_dim).to(device)
#定义判别器与生成器所使用的优化算法
optim_disc = optim.Adam(disc.parameters(),lr=lr,betas=(0.9,0.999))
optim_gen = optim.Adam(gen.parameters(),lr=lr,betas=(0.9,0.999))
#定义损失函数
criterion = nn.BCELoss(reduction="mean") #默认生成均值,也可以特定标明生成均值
4.4 训练
for epoch in range(num_epochs):
for batch_idx, (x,_) in enumerate(dataloader):
x = x.view(-1,784).to(device) #展平
batch_size = x.shape[0]
#判别器反向传播====================================================
dx = disc(x).view(-1) #判别器对真实数据的预测概率
loss_real = criterion(dx,torch.ones_like(dx)) #所有真实数据的损失均值
loss_real.backward()
D_x = dx.mean().item()
noise = torch.randn((batch_size,z_dim)).to(device)
gz = gen(noise)
dgz1 = disc(gz.detach()) #需要使用detach来阻止gz进入D的计算图,判别器对生成数据的预测概率
loss_fake = criterion(dgz1,torch.zeros_like(dgz1)) #所有生成数据的损失均值
loss_fake.backward(
D_G_z1 = dgz1.mean().item()
errorD = loss_real + loss_fake
#errorD.backward() #直接对errorD反向传播,也可分别对loss_real,loss_fake执行反向传播
optim_disc.step() #更新判别器上的权重
disc.zero_grad() #清零判别器迭代后的梯度
#生成器反向传播*====================================================
dgz2 = disc(gz) #注意,由于在此时判别器上的权重已经被更新过了,所以dgz的值会变化,需要重新生成
Gloss = criterion(dgz2,torch.ones_like(dgz2))
Gloss.backward() #反向传播
optim_gen.step() #更新生成器上的权重
gen.zero_grad() #清零生成器更新后梯度
D_G_z2 = dgz2.mean().item()