1 回归的概念 线性回归的导出
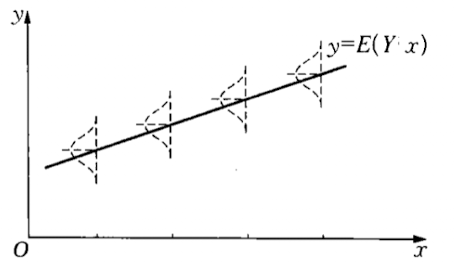
回顾 前面的定义 , 回归就是要对数值变量寻找线性关系. 如果只是二维情况, 这直观地等价于找一条直线能很好拟合坐标平面上看起来很线性的一列点.( X , Y ) 二阶矩 , 则当 X = x Y P ( ⋅ | x ) E [ Y | x ] x
图中的虚线是 Y y = E [ Y | x ]
称上面的 E [ Y | x ] Y x 回归函数 .X Y E [ Y | x ] Y Y ^ x = E [ Y | x ] X , Y
现在我们需要考虑, 把 x f ( x ) E [ Y | x ]
如果 M ( X ) E [ Y − M ( X ) ] 2 = min f E [ Y − f ( X ) ] 2 , M ( X ) Y 最小均方误差预测 .
在上述定义中, E [ Y | X ] E [ Y | X ] Y 相关系数 达到极大值 Var ( M ) Var ( Y ) Var ( M ) M ( X ) = E [ Y | X ]
对任意 f ( X ) E [ Y − f ( X ) ] 2 = E [ Y − E [ Y | X ] + E [ Y | X ] − f ( X ) ] 2 = E [ Y − E [ Y | X ] ] 2 + E [ E [ Y | X ] − f ( X ) ] 2 + 2 E [ Y − E [ Y | X ] ] [ E [ Y | X ] − f ( X ) ] , 塔式法则 , E [ Y − E [ Y | X ] ] [ E [ Y | X ] − f ( X ) ] = E E { [ Y − E [ Y | X ] ] [ E [ Y | X ] − f ( X ) ] | X } = E { [ E [ Y | X ] − f ( X ) ] E { [ Y − E [ Y | X ] ] | X } } = 0. E [ Y − f ( X ) ] 2 ≥ E [ Y − E [ Y | X ] ] 2 , M ( X ) Y
容易计算出 Cov ( Y , f ) = E [ Y − E Y ] [ f ( X ) − E f ( X ) ] = E E [ ( Y − E Y ) [ f ( X ) − E f ( X ) ] | X ] = E [ f ( X ) − E f ( X ) ] [ E [ Y | X ] − E Y ] = Cov ( f , M ) . Cov ( Y , M ) = Cov ( M , M ) = Var ( M ) Cauchy-Schwarz不等式 , ρ ( Y , f ) = Cov ( Y , f ) Var ( Y ) Var ( f ) = Cov ( M , f ) Var ( Y ) Var ( f ) ≤ Var ( M ) Var ( f ) Var ( Y ) Var ( f ) = Var ( M ) Var ( Y ) Var ( M ) = ρ ( Y , M ) .
从上面的证明看出, Y ^ x = E [ Y | x ] ε = Y − E [ Y | x ] E ε = 0 , Var ( ε ) = E ε 2 = Var ( Y ) − Var ( M ) . ε x = Y x − E [ Y | x ]
定义预测精度 λ = Var ( ε ) Var ( Y ) λ = 1 − Var ( M ) Var ( Y ) = 1 − ρ 2 ( Y , M ) . 主 要 部 分 预 测 误 差 Y x = E [ Y | x ] ⏟ 主要部分 + ε x ⏟ 预测误差 . E [ Y | x ] x E [ Y | x ] = β 0 + β 1 x 1 + ⋯ + β p x p ,
(1.1) Y x = β 0 + β 1 x 1 + ⋯ + β p x p + ε x . 1.1 正态情形
在正态情形下, 线性函数的预测是最佳的.z = ( y , x 1 , ⋯ , x p ) T ∼ N ( v , V ) p + 1 f ( z ) = ( 2 π ) − p + 1 2 ( det V ) − 1 2 exp { − 1 2 ( z − v ) T V − 1 ( z − v ) } . V − 1 = [ v 11 v T v V 22 ] v ∈ R p E y = θ , E x = μ → x φ ( x ) E [ Y | x ] = ∫ − ∞ ∞ y ( 2 π ) − p + 1 2 ( det V ) − 1 2 exp { − 1 2 ( z − v ) T V − 1 ( z − v ) } φ ( x ) − 1 d y . Q = ( z − v ) T V − 1 ( z − v ) y Q = ( y − θ ) 2 v 11 + 2 ( y − θ ) v T ( x − μ ) + ( x − μ ) T V 22 ( x − μ ) = v 11 [ y − θ + ( v 11 ) − 1 v T ( x − μ ) ] 2 + c , Y E [ Y | x ] = θ − ( v 11 ) − 1 V T ( x − μ ) x
1.2 最小均方误差线性预测
如果在 x { c 0 + c T x } M ( x ) E [ Y − M ( x ) ] 2 = min c 0 , c E [ Y − c 0 + c T x ] 2 , M ( x ) Y 最小均方误差线性预测 .
记 Cov ( Y X ) = ( σ Y 2 σ Y X σ X Y T Σ X X ) , Σ X X σ Y 2 = Var ( Y ) σ Y X = σ X Y T = ( Cov ( Y , X 1 ) , ⋯ , Cov ( Y , X p ) ) Σ X X = Cov ( X , X ) (1.2) M ( x ) = E Y − σ Y X Σ X X − 1 E x + σ Y X Σ X X − 1 x .
取 c 0 + c T x E [ Y − c 0 − c T x ] 2 = E [ ( Y − E Y ) − c ′ ( x − E x ) + ( E y − c 0 − c T E x ) ] 2 = σ Y 2 + c T Σ X X c − 2 σ Y X c + ( E Y − c 0 − c T E x ) 2 = σ Y 2 + ( Σ X X 1 2 c − Σ X X − 1 2 σ X Y T ) T ( Σ X X 1 2 c − Σ X X − 1 2 σ X Y T ) − σ Y X Σ X X − 1 σ X Y T + ( E Y − c 0 − c T E x ) 2 . c 0 , c { Σ X X 1 2 c − Σ X X − 1 2 σ X Y T = 0 E Y − c 0 − c T E x = 0 c = Σ X X − 1 σ X Y T , c 0 = E Y − σ Y X Σ X X − 1 E x .
容易看出 M ( x ) Y λ L = 1 − σ Y X Σ X X − 1 σ X Y T σ Y 2 = 1 − ρ Y , X 2 . λ L 这里的 λ
记 β 0 = E Y − σ Y X Σ X X − 1 E x β = Σ X X − 1 σ X Y T (1.3) Y = β 0 + β T x + ε . y = β 0 + β T x 回归方程 , β 回归系数 .
2 回归系数的估计 经验回归
在实际问题中, 我们无法得到总体的二阶矩, 需要用样本来估计. 设容量为 n y = ( y 1 ⋮ y n ) , X = ( x 11 ⋯ x 1 p ⋮ ⋱ ⋮ x n 1 ⋯ x n p ) , 1 = ( 1 , ⋯ , 1 ) T y = ( 1 X ) ( β 0 β ) + ε .
假设这个式子就是回归分析模型. 此时设计矩阵的秩 rank ( ( 1 X ) ) = p + 1 Z = ( 1 X ) θ = ( β 0 β T ) T y = Z θ + ε .
考虑最小二乘问题 | | y − Z θ ^ | | 2 = min θ ∈ R p + 1 | | y − Z θ | | 2 .
我们有| | y − Z θ | | 2 = | | y − Z θ ^ + Z ( θ ^ − θ ) | | 2 = | | y − Z θ ^ | | 2 + | | Z ( θ ^ − θ ) | | 2 + 2 ( θ ^ − θ ) T Z T ( y − Z θ ^ ) . | | y − Z θ | | 2 ≥ | | y − Z θ ^ | | 2 ∀ θ ∈ R p + 1 ( θ ^ − θ ) T Z T ( y − Z θ ^ ) = 0 , ∀ θ ∈ R p + 1 . Z T ( y − Z θ ^ ) = 0
Z T Z θ ^ = Z T y . 由此得到解 (2.1) θ ^ = ( Z T Z ) − 1 Z T y . θ 最小二乘估计 . 记 θ ^ = ( β ^ 0 β ^ T ) T β 0 , β 经验回归系数 . 相应的 (2.2) y ^ = β ^ 0 + β ^ T x 经验回归方程 , β ^ 0 + β ^ T x
在 p = 1
( Z T Z ) − 1 = [ ( 1 T x T ) ( 1 x ) ] − 1 = ( n ∑ i = 1 n x i ∑ i = 1 n x i ∑ i = 1 n x i 2 ) − 1 = [ n ∑ i = 1 n x i 2 − ( ∑ i = 1 n x i ) 2 ] − 1 ( ∑ i = 1 n x i 2 − ∑ i = 1 n x i − ∑ i = 1 n x i n ) , Z T y = ( ∑ i = 1 n y i , ∑ i = 1 n x i y i ) T .
有 (2.3) { β ^ 0 = ∑ i = 1 n x i 2 ∑ i = 1 n y i − ∑ i = 1 n x i ∑ i = 1 n x i y i n ∑ i = 1 n x i 2 − ( ∑ i = 1 n x i ) 2 , β ^ 1 = n ∑ i = 1 n x i y i + ∑ i = 1 n x i ∑ i = 1 n y i n ∑ i = 1 n x i 2 − ( ∑ i = 1 n x i ) 2 . (2.4) ( β ^ 0 β ^ ) = ( n 1 T X X T 1 X T X ) − 1 ( 1 T y X T y ) .
3 预测区域
我们需要衡量预测的可靠性, 也即如何找到一个区域, 它包含待预测的 y ∗ 1 − α 置信区间 ). 我们假设总体分布 y ∼ N n ( X β , σ 2 I )
设 Y ∼ N n ( μ , I ) A n B n × m
Y T A Y ∼ χ r 2 ( δ ) A r = rank ( A ) δ 2 = μ T A μ 当 Y T A Y ∼ χ r 2 ( δ ) Y T A Y ⊥ ⊥ B T Y ⟺ B T A = 0.
因为 A I − A A + ( I − A ) = I rank A + rank ( I − A ) = n Cochran定理 , Y T A Y ∼ χ r 2 ( δ )
由于 Y T A Y ∼ χ r 2 ( δ ) A U U T A U = ( I r 0 0 0 ) U = ( U 1 n × r U 2 ) Y = U X Y T A Y = X T U A U X = ∑ i = 1 r x i 2 , B T Y = B T U X . B T A = B T U ( I r 0 0 0 ) U T = 0 , B T U 1 = 0 B T Y = ( B T U 1 B T U 2 ) X = ( 0 B T U 2 ) X = B T U 2 X ( 2 ) , X ( 2 ) = ( X r + 1 , ⋯ , X n ) T
现在对回归模型 Y = X β + ε β ^ = ( X T X ) − 1 X T y 残差平方和 为 S ε 2 = | | y − x β ^ | | 2 S ε 2 = y T P X ⊥ y , P X ⊥ = I − X ( X T X ) − 1 X T y ^ = X β ^ = P X y P X = X ( X T X ) − 1 X T span { Col ( X ) }
⚠ Switch to EXCALIDRAW VIEW in the MORE OPTIONS menu of this document. ⚠ You can decompress Drawing data with the command palette: 'Decompress current Excalidraw file'. For more info check in plugin settings under 'Saving'
Excalidraw Data
Text Elements
y
在上述记号下 β ^ ∼ N p ( β , σ 2 ( X T X ) − 1 ) , y ^ ∼ N n ( X β , σ 2 P X ) , σ − 2 S ε 2 ∼ χ n − p 2 , β ^ , y ^ , S ε 2 p X
根据 引理 , 注意到 ( X β ) T P X ⊥ X β = 0 rank P X = tr P X = n − tr ( X ( X T X ) − 1 X T ) = n − tr ( ( X T X ) − 1 X T X ) = n − p .
如果在历史样本基础上已经得到回归方程 y ^ = X T β ^ x ∗ = ( x 1 , ⋯ , x p ) T x ∗ y ∗ y ∗ ∼ N 1 ( x ∗ T β , σ 2 ) y ^ ∗ = x ∗ T β ^ = x ∗ T ( X T X ) − 1 X T y y ∗ − y ^ ∗ ∼ N 1 ( 0 , σ ∗ 2 ) . y ∗ ⊥ ⊥ y y ^ ∗ σ ∗ 2 = σ 2 + σ 2 x ∗ T ( X T X ) − 1 x ∗ = σ 2 ρ 2 , ρ 2 = 1 + x ∗ T ( X T X ) − 1 x ∗ 定理 , σ − 2 S ε 2 ∼ χ n − p 2 S ε 2 ⊥ ⊥ y ∗ − y ^ ∗ T = y ∗ − y ^ ∗ S ε ρ n − p ∼ t n − p . t n − p ( α ) t n − p α 1 − α P ( | T | ≤ t n − p ( α 2 ) ) = 1 − α , y ^ ∗ ± t n − p ( α 2 ) S ε ρ ( n − p ) − 1 2
我们可以把 y 1 , y 2 x ∗ = ( x 1 ∗ , ⋯ , x p ∗ ) y = y 1 , y = y 2 R p + 1 预测带 .
如果有 m x ∗ = ( x α l ) y ∗ = ( y 1 ∗ , ⋯ , y m ∗ ) T y ^ ∗ = X ∗ β ^ = X ∗ ( X T X ) − 1 X T y y ∗ ⊥ ⊥ y ⇒ y ∗ ⊥ ⊥ y ^ ∗ E ( y ∗ − y ^ ∗ ) = 0 , Cov ( y ∗ − y ^ ∗ ) = σ 2 I m + σ 2 X ∗ ( X T X ) − 1 X ∗ T . Σ = I m + X ∗ ( X T X ) − 1 X ∗ T σ − 1 Σ − 1 2 ( y ∗ − y ^ ∗ ) ∼ N m ( 0 , I m ) σ − 2 ( y ∗ − y ^ ∗ ) T Σ − 1 ( y ∗ − y ^ ∗ ) ∼ χ m 2 . y ∗ , y ^ ∗ ⊥ ⊥ S ε 2 F = ( y ∗ − y ^ ∗ ) T Σ − 1 ( y ∗ − y ^ ∗ ) S ε 2 ⋅ n − p m ∼ F m , n − p . P ( ( y ∗ − y ^ ∗ ) T Σ − 1 ( y ∗ − y ^ ∗ ) ≤ m n − p S ε 2 F m , n − p ( α ) ) = 1 − α . c ( y ) = { y | ( y − y ^ ∗ ) T Σ − 1 ( y ∗ − y ^ ∗ ) ≤ m n − p S ε 2 F m , n − p ( α ) } R m c ( y ) y ∗ 1 − α
3.1 预测区域的精度
预测区域"包含"y ∗ m = 1 Δ = y 2 − y 1 Δ 2 = ( y 2 − y 1 ) 2 = ( t n − p ( α 2 ) ) 2 S ε 2 ( 1 + x ∗ T ( X T X ) − 1 x ∗ ) ( n − p ) − 1 . E Δ 2 = ( t n − p ( α 2 ) ) 2 σ 2 ( 1 + x ∗ T ( X T X ) − 1 x ∗ ) > ( t n − p ( α 2 ) ) 2 σ 2 . X T X 信息矩阵 , 它如果特征值很小, 则预测精度可能很低.E [ m n − p S ε 2 F m , n − p ( α ) ] = m σ 2 F m , n − p ( α ) , Σ − 1 1 m = 1
4 显著性检验
我们现在可以从样本来进行线性回归. 但是所得回归函数是否是整个原模型的好的拟合? 我们可以进行假设检验.
4.1 检验系数是否为 0 向量
为了检验模型 y = 1 β 0 + X β + ε H 0 : β = 0. H 0 H 0
为了检验 H 0 S ε 2 = min β 0 , β | | y − 1 β 0 − X β | | 2 , S 0 2 = min β 0 | | y − 1 β 0 | | 2 . S ε 2 = | | P ( 1 X ) ⊥ y | | 2 = y T P ( 1 X ) ⊥ y S 0 2 = | | P 1 ⊥ y | | 2 = y T P 1 ⊥ y . H 0 E 0 ( S 0 2 ) = E 0 ( tr ( P 1 ⊥ y y T ) ) = tr ( P 1 ⊥ E 0 ( y y T ) ) = tr ( P 1 ⊥ [ Cov y + E 0 y ( E 0 y ) T ] ) = ( n − 1 ) σ 2 . H 0 E 1 ( S 0 2 ) = ( n − 1 ) σ 2 + | | P 1 ⊥ X β | | 2 > E 0 ( S 0 2 ) . S 0 2 H 0 S 0 2 ∼ σ 2 χ n − 1 2 S H 2 = S 0 2 − S ε 2 S H 2 = y T ( P ( 1 X ) − P 1 ) y ≥ 0. S H 2 + S ε 2 = S 0 2 Cochran定理 有 σ − 2 S H 2 ∼ χ p 2 ( δ ) , σ − 2 S ε 2 ∼ χ n − p − 1 2 , F = S H 2 S ε 2 ⋅ n − p − 1 p ∼ F p , n − p − 1 , δ . H 0 δ 2 = σ − 2 β 0 1 T ( P ( 1 X ) − P 1 ) 1 β 0 = 0 F ∼ F p , n − p − 1 { F ≥ F p , n − p − 1 ( α ) }
4.2 检验分量是否为 0
我们还需要检验 H 0 i : β i = 0 β 0 = 0 y = X β ^ β ^ = ( X T X ) − 1 X T y , β ^ i = e i T ( X T X ) − 1 X T y , e i = ( 0 , ⋯ , 0 , 1 ⏟ i , 0 , ⋯ , 0 ) T c = ( X T X ) − 1 = ( c i j ) β ^ i ∼ N ( β i , σ 2 c i i ) S ε 2 = y T P X ⊥ y ⊥ ⊥ β ^ i F = β ^ i 2 c i i S ε 2 ( n − p ) . H 0 i F ∼ F 1 , n − p { F ≥ F 1 , n − p ( α ) }
如果接受 H 0 i x i i X X ∗ y = X ∗ β ∗ + ε y ^ = X ∗ β ^ ∗ β ^ ∗ = ( β ^ ∗ 1 , ⋯ , β ^ ∗ i − 1 , β ^ ∗ i + 1 , ⋯ , β ^ ∗ p ) T i
剖分 I p = ( D 1 i − 1 e i D 2 p − i ) , D = ( D 1 D 2 ) X ∗ = X D , D D T + e i e i T = I p , β ^ ∗ = ( X ∗ T X ∗ ) − 1 X ∗ T y = ( D T X T X D ) − 1 D T X T X β ^ = ( D T X T X D ) − 1 D T X T X ( D D T + e i e i T ) β ^ = D T β ^ + ( D T X T X D ) − 1 D T X T X e i β ^ i . c i = ( X T X ) − 1 e i 0 = D T e i = D T X T X c i = D T X T X ( D D T + e i e i T ) c i = D T X T X D D T c i + D T X T X e i c i i , D T X T X e i = − D T X T X D D T c i c i i β ^ ∗ = D T β ^ − D T c i β ^ i c i i .
5 回归因子挑选
上一小节介绍了用显著性检验来判断是否要加入因子. 在此基础上我们有挑选因子的逐步回归算法.y = X β + ε p − r
进行剖分 X = ( X 1 r X 2 r ) , β = ( β ( 1 ) β ( 2 ) ) r , x = ( x ( 1 ) x ( 2 ) ) r . y ^ = x T β ^ , β ^ = ( X T X ) − 1 X T y . y = X 1 β ( 1 ) + X 2 β ( 2 ) + ε ≡ X 1 β ( 1 ) + ε ∗ , E ε ∗ = X 2 β 2 y ^ ∗ = x ( 1 ) T β ^ ( 1 ) , β ^ 1 = ( X 1 T X 1 ) − 1 X 1 T y . ε ^ = Y − y ^ ε ^ ∗ = Y − y ^ ∗ E ( ε ^ 2 ) = Var ( ε ^ ) = σ 2 ( 1 + x T ( X T X ) − 1 x ) , E ( ε ^ ∗ 2 ) = Var ( ε ^ ∗ ) + ( E ε ^ ∗ ) 2 = σ 2 ( 1 + x ( 1 ) T ( X 1 T X 1 ) − 1 x ( 1 ) ) + ( E ( ε ^ ∗ ) ) 2 . E ( ε ^ ∗ ) = x T β − x ( 1 ) T ( X 1 T X 1 ) − 1 X 1 T X β = x ( 1 ) T β ( 1 ) + x ( 2 ) T β ( 2 ) − x ( 1 ) T ( X 1 T X 1 ) − 1 X 1 T ( X 1 β ( 1 ) + X 2 β ( 2 ) ) = x ( 2 ) T β ( 2 ) − x ( 1 ) T ( X 1 T X 1 ) − 1 X 1 T X 2 β ( 2 ) , ( E ε ^ ∗ ) 2 = ( x ( 2 ) − X 2 T X 1 ( X 1 T X 1 ) − 1 x ( 1 ) ) T β ( 2 ) β ( 2 ) T ( x ( 2 ) − X 2 T X 1 ( X 1 T X 1 ) − 1 x ( 1 ) ) . E ε ^ ∗ = b 预测偏差 . 由 X T X = ( X 1 T X 1 X 1 T X 2 X 2 T X 1 X 2 T X 2 ) , ( X T X ) − 1 = c = ( c 11 c 12 c 21 c 22 ) . Var ( ε ^ ) − Var ( ε ^ ∗ ) = σ 2 ( x T c x − x ( 1 ) T ( X 1 T X 1 ) − 1 x ( 1 ) ) = σ 2 x T ( c − ( ( X 1 T X 1 ) − 1 0 0 0 ) ) x = σ 2 x T ( ( X 1 T X 1 ) − 1 X 1 T X 2 c 22 X 2 T X 1 ( X 1 T X 1 ) − 1 − ( X 1 T X 1 ) − 1 X 1 T X 2 c 22 − c 22 X 2 T X 1 ( X 1 T X 1 ) − 1 c 22 ) x = σ 2 x T ( − ( X 1 T X 1 ) − 1 X 1 T X 2 I ) c 22 ( − X 2 T X 1 ( X 1 T X 1 ) − 1 I ) x = σ 2 ( x ( 2 ) − X 2 T X 1 ( X 1 T X 1 ) − 1 x ( 1 ) ) T c 22 ( x ( 2 ) − X 2 T X 1 ( X 1 T X 1 ) − 1 x ( 1 ) ) , E ( ε ^ 2 ) − E ( ε ^ ∗ 2 ) (5.1) = ( x ( 2 ) − ( X 1 T X 1 ) − 1 X 1 T X 2 x ( 1 ) ) T ( σ 2 c 22 − β ( 2 ) β ( 2 ) T ) ( x ( 2 ) − ( X 1 T X 1 ) − 1 X 1 T X 2 x ( 1 ) ) .
由于 σ 2 c 22 β ( 2 ) β ( 2 ) T | | β ( 2 ) | | 2 = β ( 2 ) T β ( 2 ) | | β ( 2 ) | | σ 2 c 22 − β ( 2 ) β ( 2 ) T y ^ y ^ ∗ E ( ε ^ 2 ) > E ( ε ^ ∗ 2 )