本节讲的算法其实有个名字 Propensity score matching (PSM), 这是业界很常用的算法.
1 一个出发点: 远远更多的对照单元
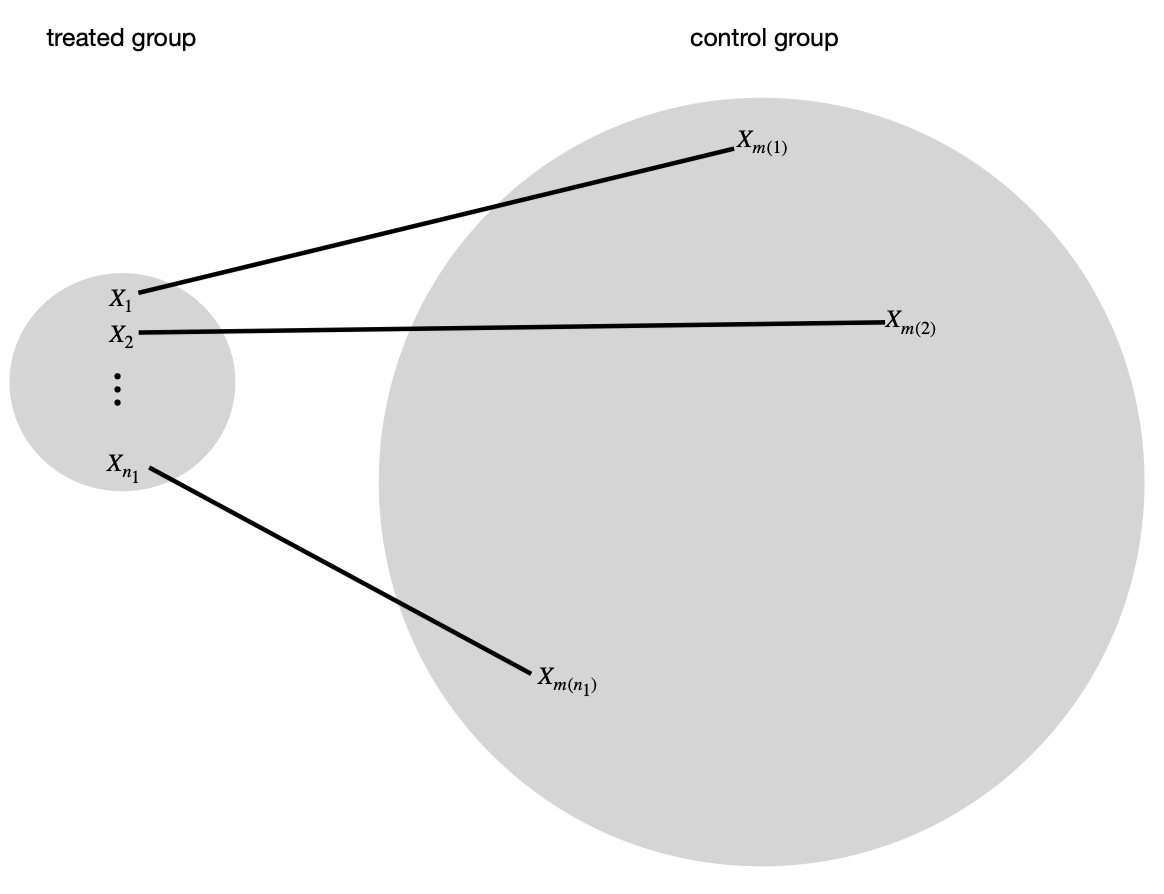
如果在实验/对照的观察性实验中, 对照组的单元数量 . 对实验组的 , 我们在对照组找一个 使得协变量 . 理想情况下这是个双射, 且倾向得分 . 因此
也即给定一一分配到两个组的要求和协变量, 实验组分配和 MPE 一致. 这样我们可以用 FRT 或者 Neyman 等方法当作 MPE 一样分析.
但因为 , 我们可以找到 个匹配的对照组. 如果 会变化, 这称为 可变比例匹配 (variable-ratio matching).
如果是完美匹配, 我们可以用 MPE 那套分析. 但是大多数情况下 并不能对所有单元成立.
2 一个更复杂但现实的情形
即使对照组很大, 我们也经常得不到完美的匹配. 我们只能得到 , 或者 在某些距离度量下很小. 例如我们定义 这里 是个距离度量. 通常的取法是 或 Mahalanobis 距离 这里 是 的协方差矩阵 (可以是整个群体或者仅仅对照组).
这里有一些问题.
- 拓展到一对 的讨论.
- 无放回匹配的讨论. 我们主要用的是有放回匹配, 通常匹配质量更高, 但是一个单元可能会被匹配多次, 引入了数据依赖性. 而无放回匹配虽然涉及计算量巨大的离散优化, 但是匹配单元间更有独立性.
- 匹配后的数据协变量依然有细微差异, 所以要在匹配的数据上跑 OLS, 抹平残差.
- 纬度灾难: 如果 是高维的, 则 可能一直很大. 此时我们不得不删去难以匹配的单元, 但这也改变了我们感兴趣的研究人群.
上述问题很难避免. 例如, 如果 , 则 这意味着它有均值 和方差 . 对于大的 , 不完美的匹配会带来因果效应的更大偏差. 所以我们必须要进行一些降维, 而倾向得分就可以在这里使用.
3 平均因果效应的匹配估计量
我们取标准的观察性实验设置 .
3.1 点估计和偏差修正
我们考虑有放回的 配对. 对实验单元 , 我们可以把潜在结果归因为 这里 是 在对照组中的匹配单元. 例如, 我们可以对对照组的所有 计算 , 然后定义 是所有让 最小的 的集合.
对对照单元 , 我们可以简单令 , 然后令 这里 是 在实验组中的匹配单元.
匹配估计量为 它的偏差实际上是不可忽略的, 特别当 是多维的, 且实验/对照组单元数量相当. 我们可以用下面的估计量来估计偏差: 这里 是预测的结果, 例如用 OLS.
对实验单元 , 估计的偏差是 它修正了协变量错误匹配带来的对照组潜在结果的差距; 类似地对对照单元 , 最后修正偏差了的估计量为 它有如下的线性展开.
我们有 其中 而 是 单元被匹配的次数.
这个线性展开导出一个简单的方差估计量. 把 看作 的样本均值, 我们有
3.2 与双重稳健估计量的关联
偏差修正的匹配估计量和双重稳健估计量有紧密的关联. 如果我们修改一下残差 则它们都和这个结果回归估计量相同.
对平均因果效应, 回顾 结果回归估计量 和 双重稳健估计量 进一步地 形式类似 :
从这个命题, 我们可以把匹配看作一个倾向得分的非参数估计方式, 得到的 看作一个双重稳定估计量. 例如, 应该接近 . 当实验单元有小的 时, 会很大, 它会匹配到很多对照单元, 导致大的 以及大的 . 但是这种连接也会有一个显然的问题. 如果固定 , 则用 估计 会有"很大噪音" (也即估计量方差大, 极不稳定, 因为你观察的数据是有限的、定死的). 所以我们必须要要求 随着样本量一起增大才可能提升这个估计量的表现.
4 实验组中平均因果效应的匹配估计量
对实验组的平均因果效应 对于缺失的潜在结果, 用对照组的进行填补即可: (也就是实验组的人的拟合结果平均一下). 这对于多维的 也是有偏差的. 它的偏差可以估计为 最终修正偏差的估计量是 也有线性展开:
我们有
我们可以把 看作 乘以 的样本均值, 所以一个直观的方差估计量是
类似 前面的讨论, 我们能把双重稳健/偏差修正的配对估计量, 和结果回归估计量比较. 回顾 进一步地, 我们可以验证 形式类似 .
这说明本质上匹配用了 来估计接受实验处理的几率.